
Apache Spark powers large-scale data analytics and machine learning, but as workloads grow exponentially, traditional static resource allocation leads to 30–50% resource waste due to idle Executors and suboptimal instance selection.
To solve this, organizations are adopting Karpenter, a Kubernetes-native autoscaler that significantly improves cost efficiency by:
- Intelligent Scheduling – Dynamically analyzing pod resource demands and selecting the optimal instance mix (e.g., Spot Instances, high-efficiency machines).
- Rapid AutoScaling – Provisioning nodes within 40–45 seconds at job startup and automatically reclaiming resources upon completion.
- Resource Consolidation – Aggregating fragmented small resource requests into larger nodes, boosting utilization to 85%+.
By enabling on-demand, cost-optimized infrastructure scaling, Karpenter helps Spark users maximize performance while minimizing cloud costs.
Why Karpenter?
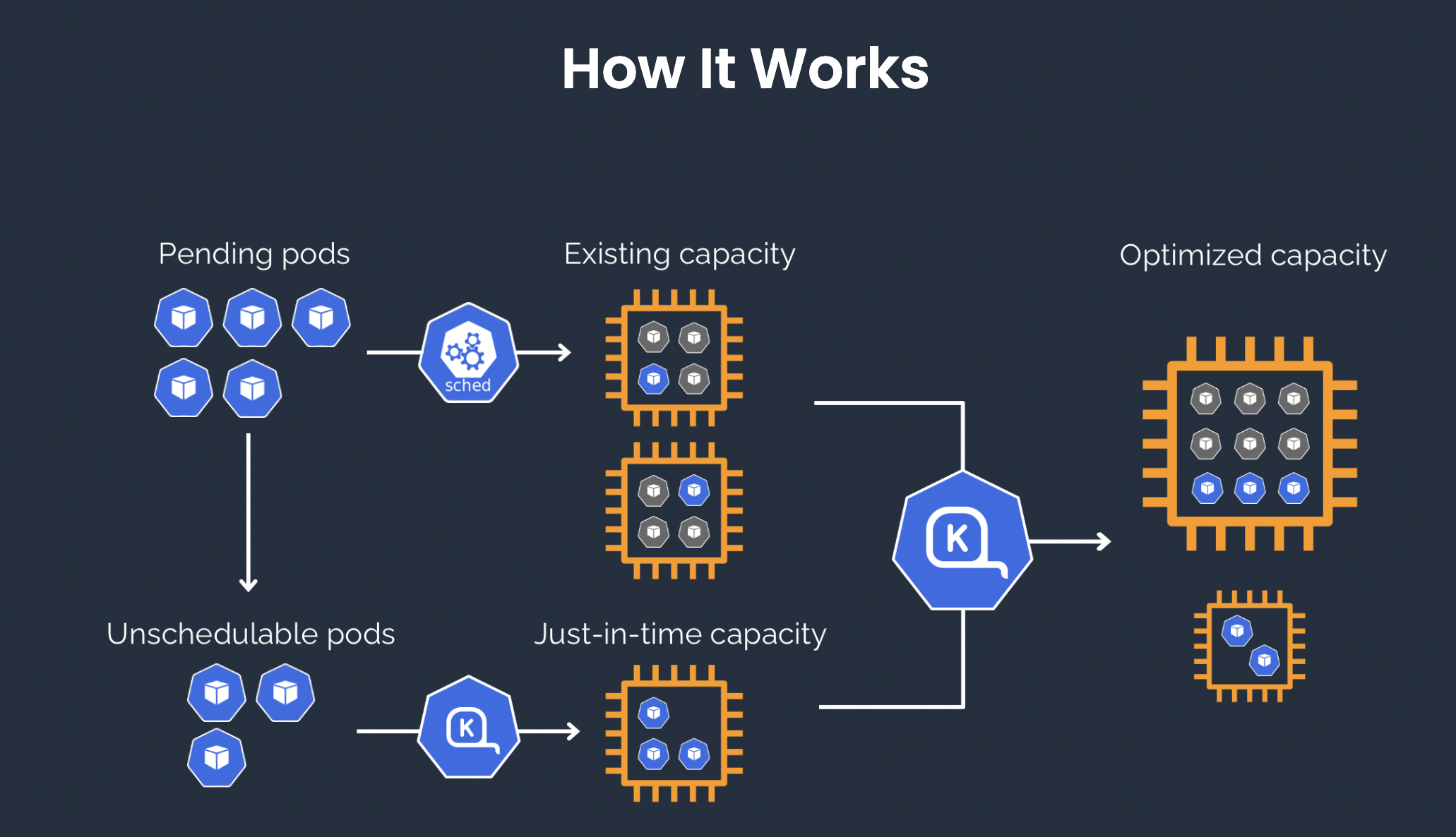
Karpenter is an intelligent autoscaler for Kubernetes, designed to maximize resource efficiency and reduce scheduling latency. It instantly detects and responds to pending pods, intelligently selecting the optimal node type and automatically provisioning or terminating instances. With a response time of just 40–45 seconds, Karpenter is significantly faster than Cluster Autoscaler's minute-level scaling.
Designed for batch processing workloads like Spark, Karpenter enables on-demand scaling of Executor node pools, leveraging Spot Instances to select the most cost-effective machine types. This leads to over 90% cloud cost savings while aggregating fragmented resources to maximize cluster utilization and efficiency.
Optimizing Spark Costs with Karpenter
1. Create a Cluster
You can explore various Karpenter implementations and in this blog we will focus on AWS.

1.1 Create a Cluster via Terraform
To create a Kubernetes cluster in the cloud using Terraform, type the command:
aws configure
git clone https://github.com/cloudpilot-ai/examples.git
cd examples/clusters/eks-spot
terraform init
terraform apply --auto-approve
Get the cluster kubeconfig.
export KUBECONFIG=~/.kube/demo
aws eks update-kubeconfig --name cluster-demonstration
1.2 Check Cluster Status
kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-xx-xx.us-east-2.compute.internal Ready <none> 12m v1.32.1-eks-5d632ec
ip-10-0-xx-xx.us-east-2.compute.internal Ready <none> 12m v1.32.1-eks-5d632ec
2. Deploy Spark Operator
The Spark Operator enables the automated deployment and management of Spark job lifecycles within a Kubernetes cluster.
2.1 Install Spark-Operator
# Add the Helm repository
helm repo add spark-operator https://kubeflow.github.io/spark-operator
helm repo update
# Install the operator into the spark-operator namespace and wait for deployments to be ready
helm install spark-operator spark-operator/spark-operator \
--namespace spark-operator --create-namespace --wait
Note: The Spark History Server also needs to be installed, though it is not listed separately here.
2.2 Test Spark
# Create an example application in the default namespace
kubectl apply -f https://raw.githubusercontent.com/kubeflow/spark-operator/refs/heads/master/examples/spark-pi.yaml
# Get the status of the application
kubectl get sparkapp spark-pi
3. Deploy Karpenter(karpenter-provider-aws)
You can refer to the documentation to learn how to deploy Karpenter.
3.1 Configure environment variables:
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.3.1"
export K8S_VERSION="1.32"
export AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
export CLUSTER_NAME="${USER}-karpenter-demo"
export AWS_DEFAULT_REGION="us-west-2"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT="$(mktemp)"
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
3.2 Install Karpenter
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
3.3 Create NodePool/EC2NodeClass
You can also specify the instance family through the nodepool to schedule the desired instance types with different specifications (as shown below).
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h # 30 * 24h = 720h
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@${ALIAS_VERSION}"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
4. Testing Spark Job Autoscaling
4.1 Modify Spark-Pi
To minimize running costs while ensuring stability, we will run the driver on On-Demand instances and the executors on Spot instances. Here’s why:
1. Driver’s Importance and Stability Requirements
The driver is the core of a Spark job. It coordinates the entire job, assigns tasks to executors, monitors task execution, and collects the results.
Running the driver on Spot instances may lead to job failure if the instance is interrupted. Since Spot instances can be reclaimed at any time, the driver must be stable. To avoid job failure, the driver is typically deployed on On-Demand instances, which are more stable.
2. Executor Fault Tolerance and Flexibility
Executors perform the actual computation tasks and can dynamically start or stop during job execution.
While Spot instances have a higher risk of interruptions, they are often more cost-effective than On-Demand instances, making them ideal for compute-intensive tasks.
If an executor on a Spot instance is terminated, Spark automatically reschedules the task to another executor. This fault tolerance ensures that jobs continue even when some Spot instances are interrupted.
By using node affinity policies, we can achieve differentiated node elasticity and scheduling for the driver and executors.
spec:
arguments:
- "5000"
deps: {}
driver:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/capacity-type
operator: NotIn
values:
- spot
cores: 1
labels:
version: 3.5.3
memory: 512m
serviceAccount: spark-operator-spark
executor:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
cores: 1
instances: 20
labels:
version: 3.5.3
memory: 512m
4.2 Check the node creation status in Karpenter
kubectl get nodeclaims
NAME TYPE ZONE NODE READY AGE
cloudpilot-general-2nfw7 m7a.2xlarge us-east-2c ip-10-0-xx-xx.us-east-2.compute.internal True 20m
cloudpilot-general-cqz29 m6a.4xlarge us-east-2b ip-10-0-xx-xx.us-east-2.compute.internal True 23m
4.3 Wait for the Spark job to complete
kubectl get sparkapplications spark-pi
NAME STATUS ATTEMPTS START FINISH AGE
spark-pi COMPLETED 1 2025-03-06T10:23:14Z 2025-03-06T10:25:18Z 45m
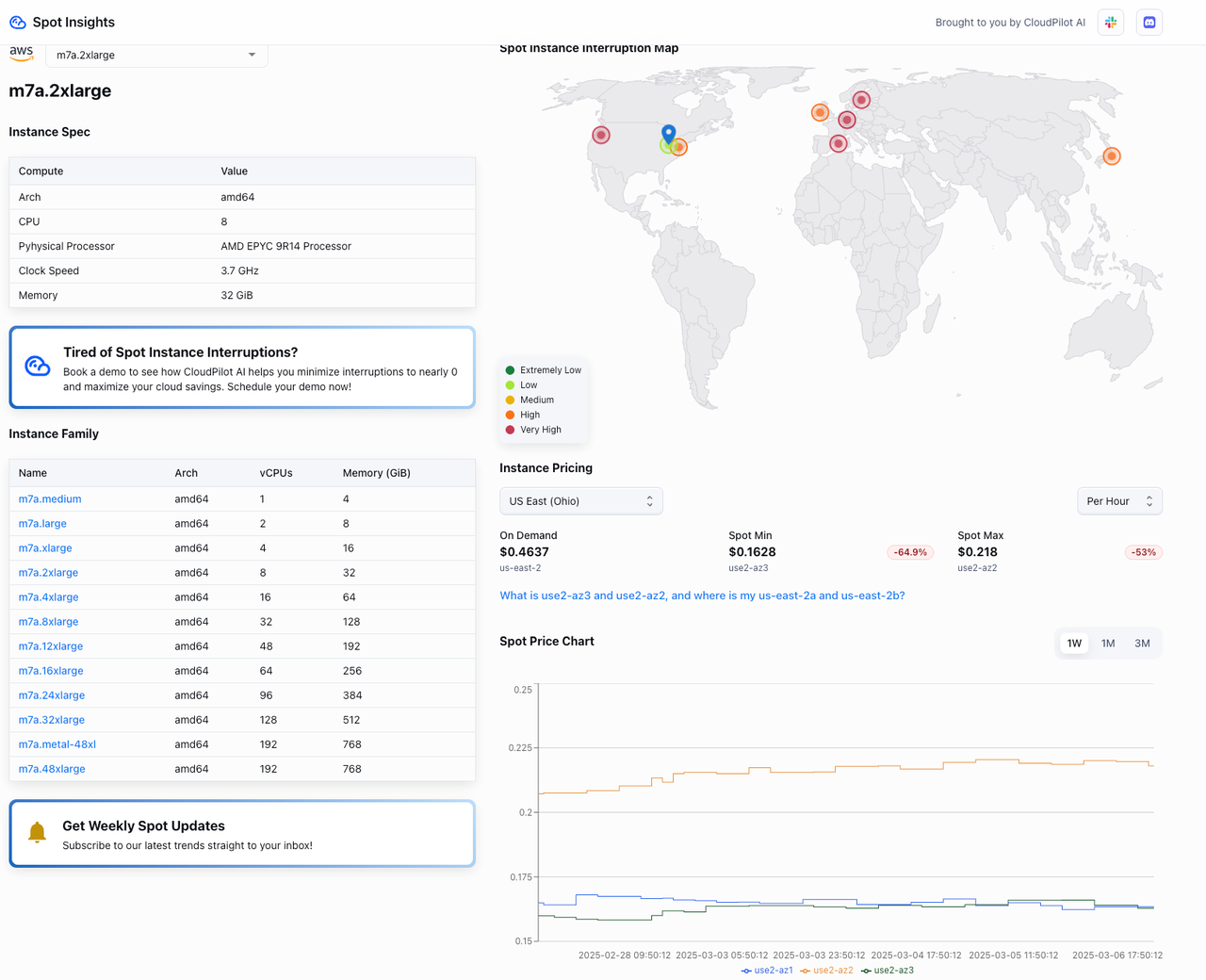
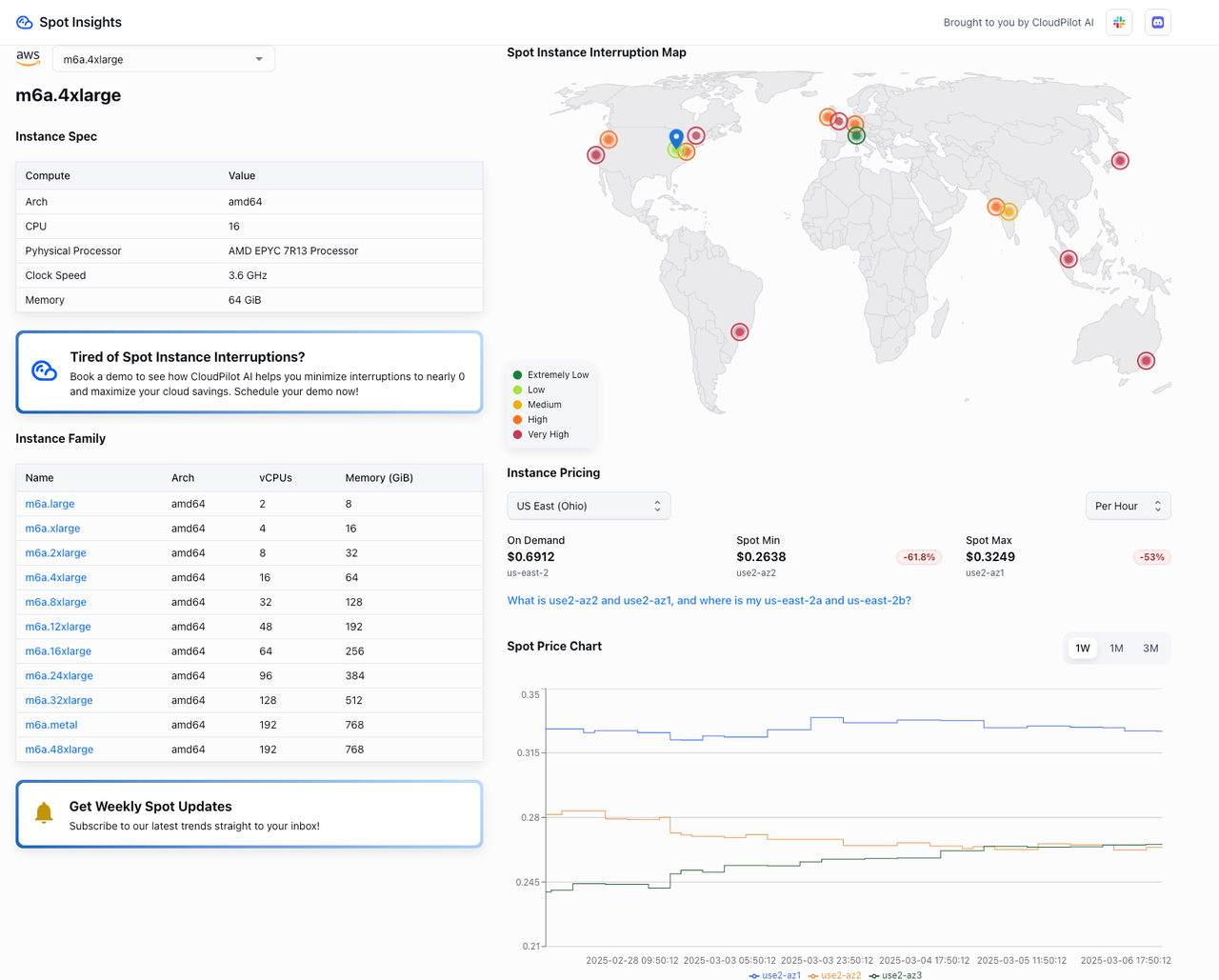
4.4 Instance Cost Consumption
In this Spark job, Karpenter dynamically provisioned 2 Spot instance nodes (types: m7a.2xlarge/m6a.4xlarge) based on the resource requirements of the executors. Once the job completed, Karpenter automatically reclaimed the nodes, ensuring resources weren’t left idle.
Here’s a breakdown from our comparison:
- Spot Instance Costs: Just 10-40% of the cost of On-Demand instances (as shown below).
- Overall Cost Comparison: When compared to traditional Cluster Autoscaler solutions, Karpenter's instance selection algorithm and fragmented resource aggregation reduced costs by more than 80%.
- For Long-Term Subscriptions: In scenarios where fixed resources are used, switching to Karpenter’s elastic architecture eliminates idle resources, potentially cutting long-term costs by 40-60%.
The images below display the real-time pricing for m7a.2xlarge and m6a.4xlarge. They're sourced from Spot Insights, a tool that provides AWS Spot instance prices and interruption rates. Feel free to check it out!
5. (Optional) Delete Spark Job
kubectl delete -f https://raw.githubusercontent.com/kubeflow/spark-operator/refs/heads/master/examples/spark-pi.yaml
6. (Optional) Uninstall Karpenter
helm uninstall karpenter --namespace karpenter-system
kubectl delete ns karpenter-system
Conclusion
This blog demonstrates how to combine Spark jobs with Karpenter to dynamically schedule AWS Spot instances, achieving over 90% significant cost savings.
We walk through the entire process, from cluster setup, Spark Operator deployment, Karpenter configuration, to Spark job autoscaling and cost optimization.
By providing detailed deployment steps and configuration examples, we show how to leverage Karpenter's autoscaling capabilities within a Kubernetes environment to maximize resource utilization and effectively reduce computing costs. This offers a highly efficient and cost-effective cloud computing solution for organizations heavily using Spark.









