
Kubernetes offers a rich ecosystem of autoscaling tools, but navigating through them can feel like walking through a maze. If you've already read our Kubernetes Autoscaling 101 or explored Kubernetes scheduling strategies, you're likely ready for a deeper dive into how the major autoscalers stack up.
In this post, we compare five core tools in the Kubernetes autoscaling toolbox:
- Horizontal Pod Autoscaler (HPA)
- Vertical Pod Autoscaler (VPA)
- Cluster Autoscaler (CA)
- Karpenter
- KEDA (Kubernetes Event-driven Autoscaler)
We'll help you understand their purposes, differences, limitations, and real-world use cases, so you can make the right choice for your workloads.
Autoscaling Dimensions in Kubernetes
Before comparing the tools, it's important to distinguish the core dimensions of autoscaling:
- Pod-level scaling: Adjusting the number of pod replicas based on workload demand.
- Resource-level scaling: Adjusting pod resource requests (CPU, memory) to reflect actual usage.
- Cluster-level scaling: Adjusting the number and type of nodes to meet aggregate resource demand.
- Event-driven scaling: Scaling based on external metrics like queue length or job backlog.
No single tool addresses all these layers comprehensively. The following sections analyze each component by its technical capabilities and trade-offs.
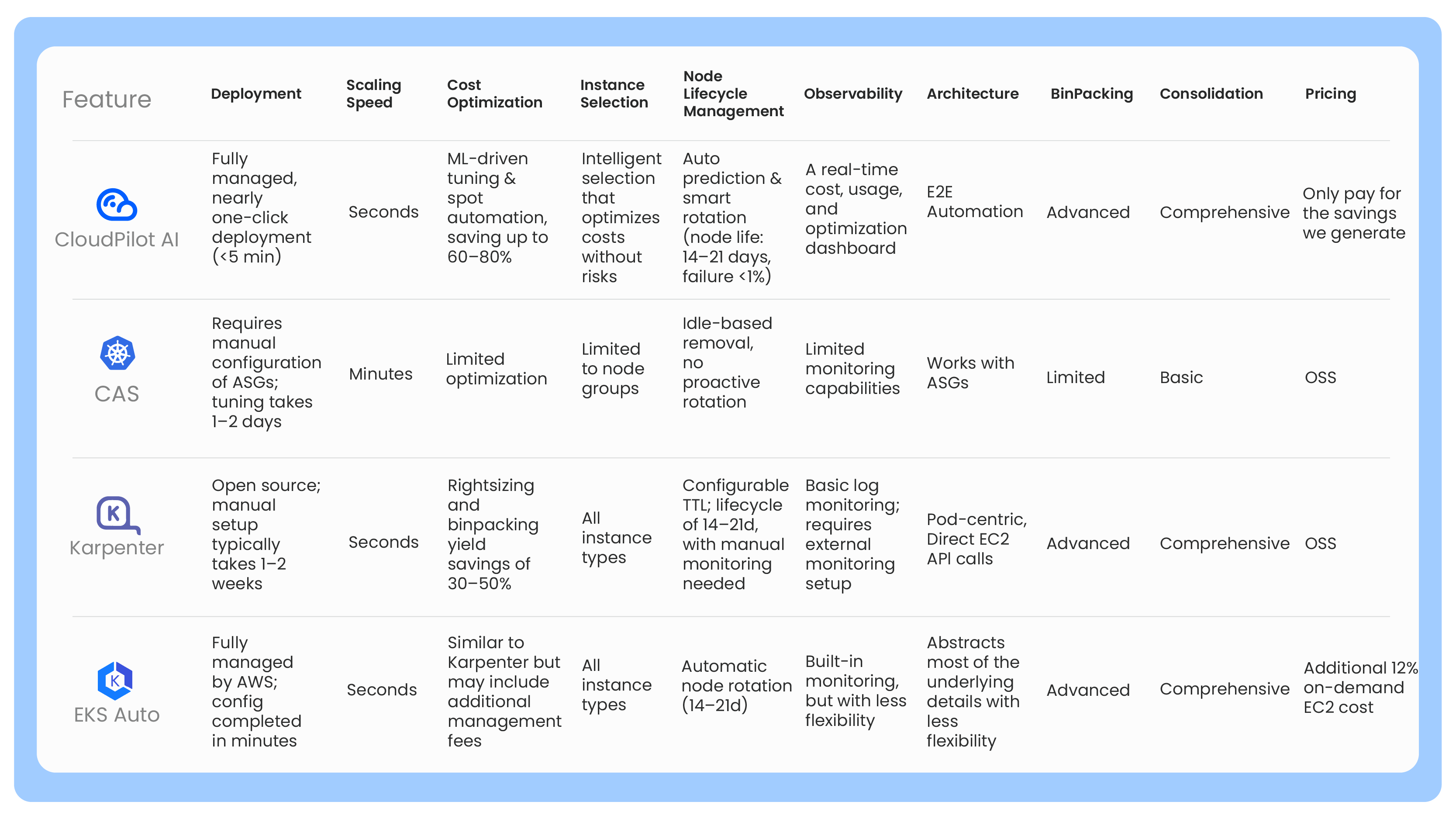
TLDR; Comparison Matrix
| Feature | HPA | VPA | Cluster Autoscaler | Karpenter | KEDA |
|---|---|---|---|---|---|
| Pod Scaling | ✅ | ❌ | ❌ | ❌ | ✅ |
| Resource Adjustment | ❌ | ✅ | ❌ | ❌ | ❌ |
| Node Scaling | ❌ | ❌ | ✅ | ✅ | ❌ |
| External Metric Scaling | ✅ (via API) | ❌ | ❌ | ❌ | ✅ |
| Works with HPA | N/A | ⚠️ Not recommended | ✅ | ✅ | ✅ |
| Works with VPA | ⚠️ Conflict on CPU/mem | N/A | ✅ | ✅ | ✅ |
| Reaction Time | Moderate (15s interval) | Slow (minutes) | Slow (minutes) | Fast (real-time) | Fast (depends on polling) |
| Stateful Workload Support | Partial | Yes | Yes | Yes | No |
| Cost Optimization Capabilities | No | Indirect (via tuning) | Partial | Yes (Spot, bin-packing) | Indirect |
Horizontal Pod Autoscaler (HPA)
The Horizontal Pod Autoscaler automatically adjusts the number of pod replicas based on observed metrics such as CPU or memory usage, or custom application-level signals.
It runs as a control loop inside the kube-controller-manager, polling metrics at a default interval of 15 seconds. This interval can be customized using the --horizontal-pod-autoscaler-sync-period flag.
HPA relies on the metrics server or the custom metrics API and calculates desired replicas using a formula:
desiredReplicas = ceil(CurrentReplicas × (CurrentMetric / TargetMetric)).
It works well for stateless services experiencing fluctuating CPU or memory load and supports integration with external metrics.
However, HPA does not modify pod resource requests, which are handled by the Vertical Pod Autoscaler. It also doesn't provision infrastructure and cannot scale workloads to zero. In volatile environments, it may require tuning to avoid rapid scale-in/scale-out cycles.
Vertical Pod Autoscaler (VPA)
The Vertical Pod Autoscaler adjusts pod resource requests over time by analyzing historical usage. It consists of three components:
- Recommender: Analyzes usage data and generates resource recommendations
- Updater: Evicts pods and triggers rescheduling with updated requests
- Admission Controller: Injects recommendations at pod creation
VPA supports two modes: recommendation-only and enforcement. In enforcement mode, pods are automatically restarted when resource values change, which can be disruptive in production environments. Metrics are collected using container usage histograms.
This is well-suited for workloads with stable, predictable usage patterns, such as batch jobs or memory-heavy applications. It helps eliminate over-provisioning and is often used in CI/CD pipelines to right-size resources.
However, VPA does not handle replica scaling or infrastructure management. When used alongside HPA, care must be taken to avoid conflicts on shared metrics like CPU.
Cluster Autoscaler (CA)
Cluster Autoscaler adjusts the size of the Kubernetes cluster by adding nodes when pods are unschedulable, and removing underutilized nodes when they can safely be drained. It does not use direct usage metrics, instead, it reacts to scheduling failures.
It integrates with cloud-native node group abstractions such as AWS Auto Scaling Groups or GCP Managed Instance Groups. The default scale-down delay is 10 minutes, and settings can be tuned to fit workload patterns. It respects PodDisruptionBudgets, taints, and labels.
CA is widely used in managed Kubernetes services and pairs well with HPA. However, it requires pre-defined node groups and lacks flexibility in dynamically choosing instance types. Its scale-up decisions are intentionally conservative, and fragmentation is common in clusters with mixed workloads.
Karpenter
Karpenter is a modern replacement for Cluster Autoscaler, designed for fast and flexible node provisioning without relying on statically defined node groups. It watches unschedulable pods and reacts in real time by launching appropriate compute resources via cloud APIs such as AWS EC2 CreateFleet.
Karpenter introduces custom resource definitions (NodeClass and NodePool) that define provisioning strategies, including instance types, architectures, capacity types (Spot or On-Demand), and availability zones. It emphasizes cost efficiency and topology-aware placement, and includes features like node consolidation and drift detection.
Compared to Cluster Autoscaler, Karpenter offers significantly faster provisioning and greater flexibility. It supports Spot instance usage, real-time bin-packing, and custom scheduling constraints. However, it lacks built-in budgeting controls and does not use metric-based thresholds, only unschedulable pod signals trigger provisioning.
Using Karpenter with CloudPilot AI
Karpenter brings flexibility and speed to node provisioning, but it does not account for historical price trends, real-time Spot interruption predictions, or cost-driven provisioning policies.
This is where CloudPilot AI enhances Karpenter-based setups. By integrating directly with Karpenter's provisioning decisions, CloudPilot AI offers:
- Intelligent Spot instance selection based on 45-minute interruption forecasts
- Historical prices across availability zones and instance types
- Custom cost and reliability trade-offs configurable per workload
- Real-time avoidance of unstable or spiky markets to reduce node churn
Teams running Karpenter can use CloudPilot AI to ensure every provisioning decision balances cost, reliability, and availability, not just fit and speed. The result is a smarter Karpenter setup with significantly improved cloud efficiency, especially for production clusters running on Spot.
KEDA, Kubernetes Event-Driven Autoscaler
KEDA enables autoscaling based on external or event-driven signals rather than internal metrics like CPU. These signals may include queue depth, request rate, or time-based schedules. KEDA introduces ScaledObject and ScaledJob resources that define triggers and link them to workloads.
It supports over 50 built-in scalers for systems like Kafka, Redis, Prometheus, and AWS SQS. KEDA polls these systems and publishes metrics to the Kubernetes API, allowing HPA to consume them. It can scale workloads from and to zero, which is essential for event-driven microservices and job queues.
KEDA integrates well with CI/CD workflows and stateless workloads. It is reactive and lightweight, but does not manage infrastructure or node provisioning. Its responsiveness depends on polling intervals, and scalers must be secured and configured for each environment.
Real-World Patterns
In production environments, autoscalers are rarely used in isolation. Below are practical combinations adopted by many SRE and DevOps teams:
1. Stateless Web Services
Use HPA to scale based on CPU or latency, and pair it with Karpenter for real-time node provisioning and cost-aware scaling. CloudPilot AI takes this further by handling Spot Instance automation, predicting and managing interruptions, selecting stable Spot pools, and falling back to on-demand when necessary.
2. Batch Jobs and ML Pipelines
Run VPA in recommendation mode to fine-tune resource requests, while Karpenter provisions optimal compute types for each run. CloudPilot AI enhances this pattern with intelligent selection across 800+ instance types, automatically choosing cost-efficient compute for short-lived, bursty, or GPU-heavy workloads.
3. Queue-Based Workers
Combine KEDA for external metric scaling with Karpenter to handle sudden bursts in demand with Spot or On-Demand nodes. CloudPilot AI adds confidence to this burst scaling by automatically selecting reliable nodes with minimal startup time.
4. Legacy or Managed Environments
Use HPA alongside Cluster Autoscaler when pre-defined node groups and more conservative scaling behavior are required.
5. Multi-tenant Clusters with Fragmentation
In multi-tenant platforms or internal developer platforms (IDPs), resource fragmentation is common. Use HPA for workload-level scaling, Karpenter for constraint-aware node provisioning, and strict topology rules to reduce underutilized resources. CloudPilot AI plays a critical role here by intelligently matching workloads to the right instances in real time, minimizing over-provisioning and cutting costs cluster-wide.
Conclusion
The Kubernetes autoscaling ecosystem is modular by design. Each tool addresses a different layer: pods, resources, infrastructure, or external load. For production-grade reliability and cost-efficiency, a composable autoscaling strategy is essential.
If your current scaling setup relies solely on HPA and Cluster Autoscaler, you're likely leaving efficiency, resilience, and cost savings on the table. CloudPilot AI complements tools like Karpenter by automating Spot Instance management and intelligently selecting optimal nodes across 800+ instance types, helping teams scale smarter and spend less.
Do you have any idea about autoscaling resources? Drop us a message in our Slack/Discord instance — we'd love to share your experience.
Frequently Asked Questions (FAQ)
Can I use HPA and VPA together?
Not easily. If both act on CPU or memory metrics, they will interfere with each other. One will try to adjust pod count based on usage, while the other adjusts the resource request, leading to unstable behavior. Limited combinations are possible when HPA uses external metrics and VPA avoids CPU/memory enforcement.
Does Karpenter replace Cluster Autoscaler?
Functionally, yes—for most dynamic environments. Karpenter offers faster provisioning, Spot instance support, and flexible node shape selection. However, it currently lacks mature multi-cloud support and budgeting controls that CA may offer when tied to managed node groups.
Is KEDA only useful for serverless or event-driven apps?
Not exclusively. KEDA works well in any situation where workload volume is not tied to CPU or memory—such as queue length, HTTP traffic, or cron schedules. It enables scaling patterns not achievable with metric-based autoscalers alone.
When should I use VPA?
Use VPA in recommendation mode to fine-tune long-running or batch workloads. Enforcement mode should be reserved for non-disruptive environments, as it triggers pod evictions on resource updates.
How do I combine these tools in production?
A typical production setup involves:
- HPA for CPU-based scaling of stateless services
- Karpenter for infrastructure provisioning
- KEDA for job or queue-driven applications
- VPA for resource optimization in non-latency-sensitive workloads Each autoscaler operates at a different layer of the system, and with careful configuration, they can coexist without conflict.








