
In the age of cloud-native infrastructure, Kubernetes has become the standard for deploying scalable, containerized workloads. But as companies embrace elastic compute and autoscaling, one challenge often surfaces: skyrocketing AWS bills.
If your workload runs on Amazon EKS, how your pods are scheduled can drastically affect cost efficiency. In this article, we’ll explore Kubernetes scheduling strategies that can reduce your AWS costs—without compromising performance or availability.
Why Scheduling Matters for Cost
Kubernetes scheduling is not just about making workloads run—it's about where and how they run. Every pod scheduled translates into an EC2 instance provisioned by the cluster autoscaler or tools like Karpenter. Poor scheduling leads to:
- Underutilized instances
- Bin-packing inefficiencies
- Over-reliance on On-Demand nodes
- Wasted compute from anti-affinity misconfigurations
The good news? You can influence scheduling decisions to achieve cost-optimized bin packing, better Spot usage, and improved node lifecycle efficiency.
1. Bin Packing: The Foundation of Efficient Scheduling
Kubernetes does not aggressively bin-pack pods by default. Its default scheduler prioritizes balanced resource allocation over maximum density, which may lead to fragmented resource usage.
How to Enable Cost-Efficient Bin Packing:
- Use the
topologySpreadConstraintsonly where needed. Overuse causes pods to spread unnecessarily, wasting capacity. - Leverage
podAffinityandpodAntiAffinitywith care. Avoid global anti-affinity unless absolutely necessary. - Use consolidation tools like Karpenter with
consolidationPolicyto actively remove underutilized nodes.
💡 Pro tip: Use the least-waste bin-packing strategy with Karpenter to prioritize dense scheduling.
2. Spot Instances: Scheduling for Interruption-Aware Savings
Spot Instances offer up to 90% discounts compared to On-Demand, but come with the risk of interruption. To safely use Spot, you must schedule pods strategically.
Key Tactics:
-
Taint-based Spot scheduling: Use
NoScheduletaints on Spot nodes to prevent critical pods from being scheduled there, and apply appropriate tolerations for tolerant workloads.taints: - key: "k8s.amazonaws.com/lifecycle" value: "Ec2Spot" effect: "NoSchedule" -
Multiple Spot capacity pools: Diversify instance types across AZs to minimize simultaneous interruptions.
-
Use node selectors and affinities to push non-critical workloads to Spot nodes.
-
Use Spot Insights to query real-time spot prices and interruptions across available zones.
🛡️ Combine this with CloudPilot AI's 45-minute interruption prediction and automatic fallback to handle draining safely.
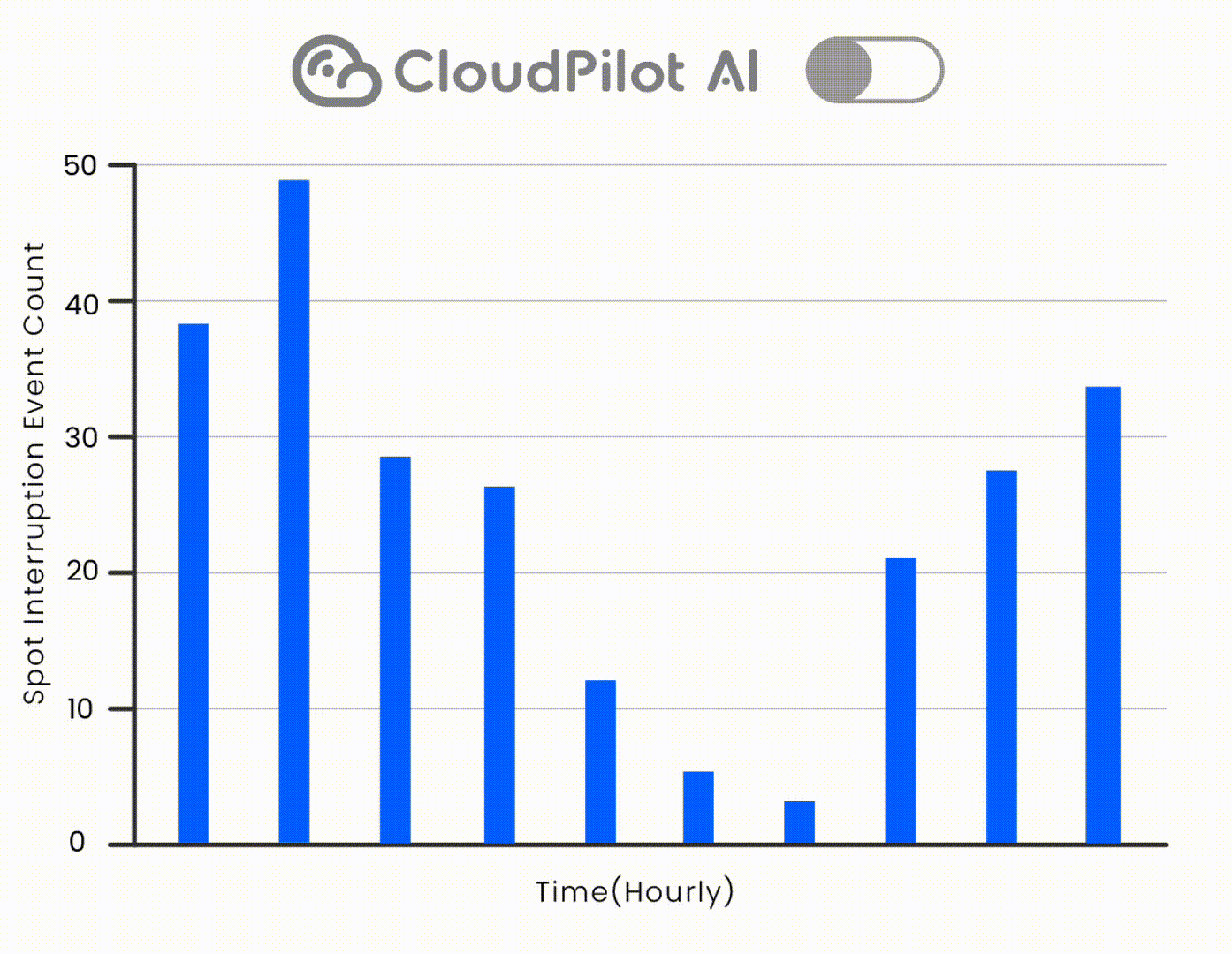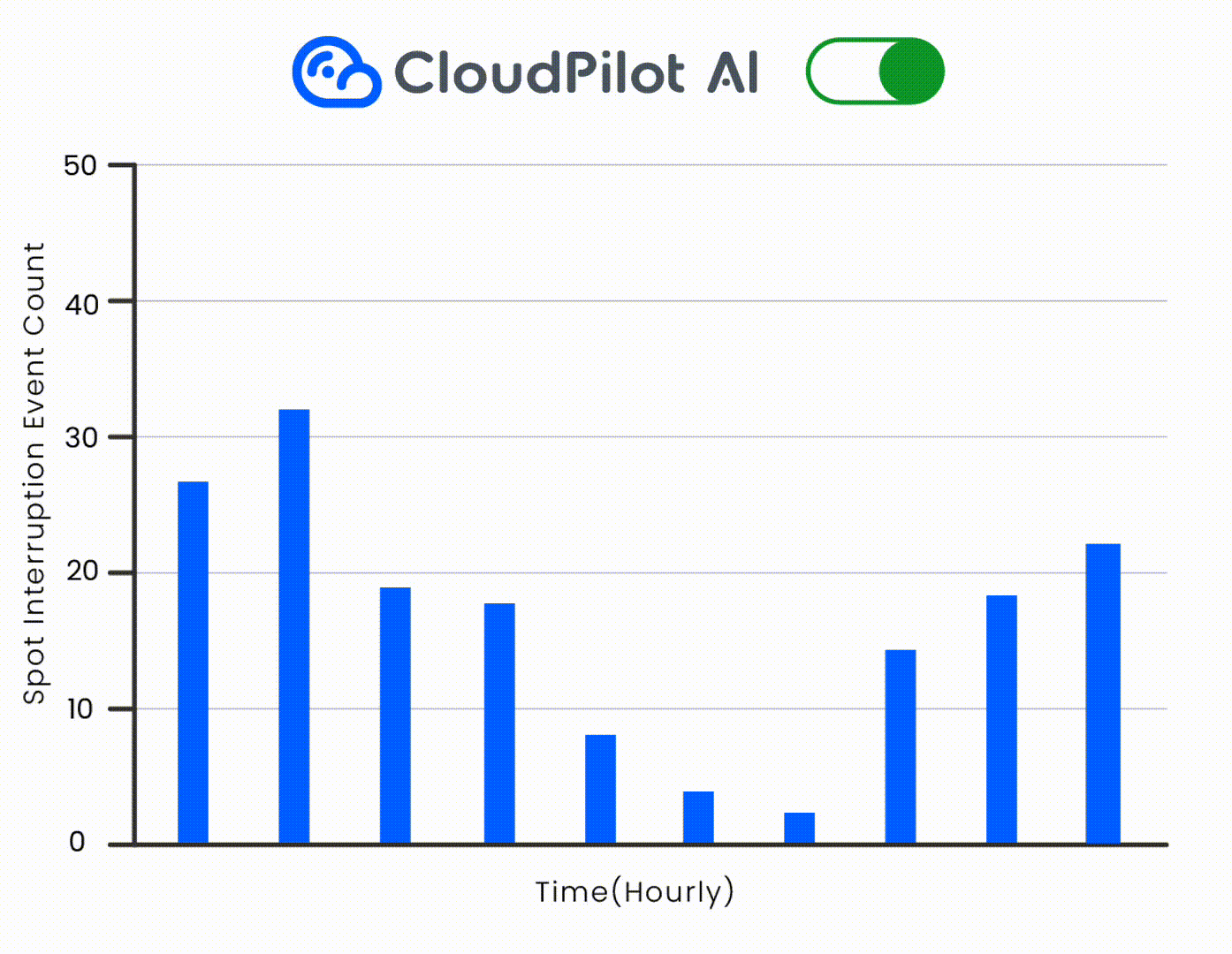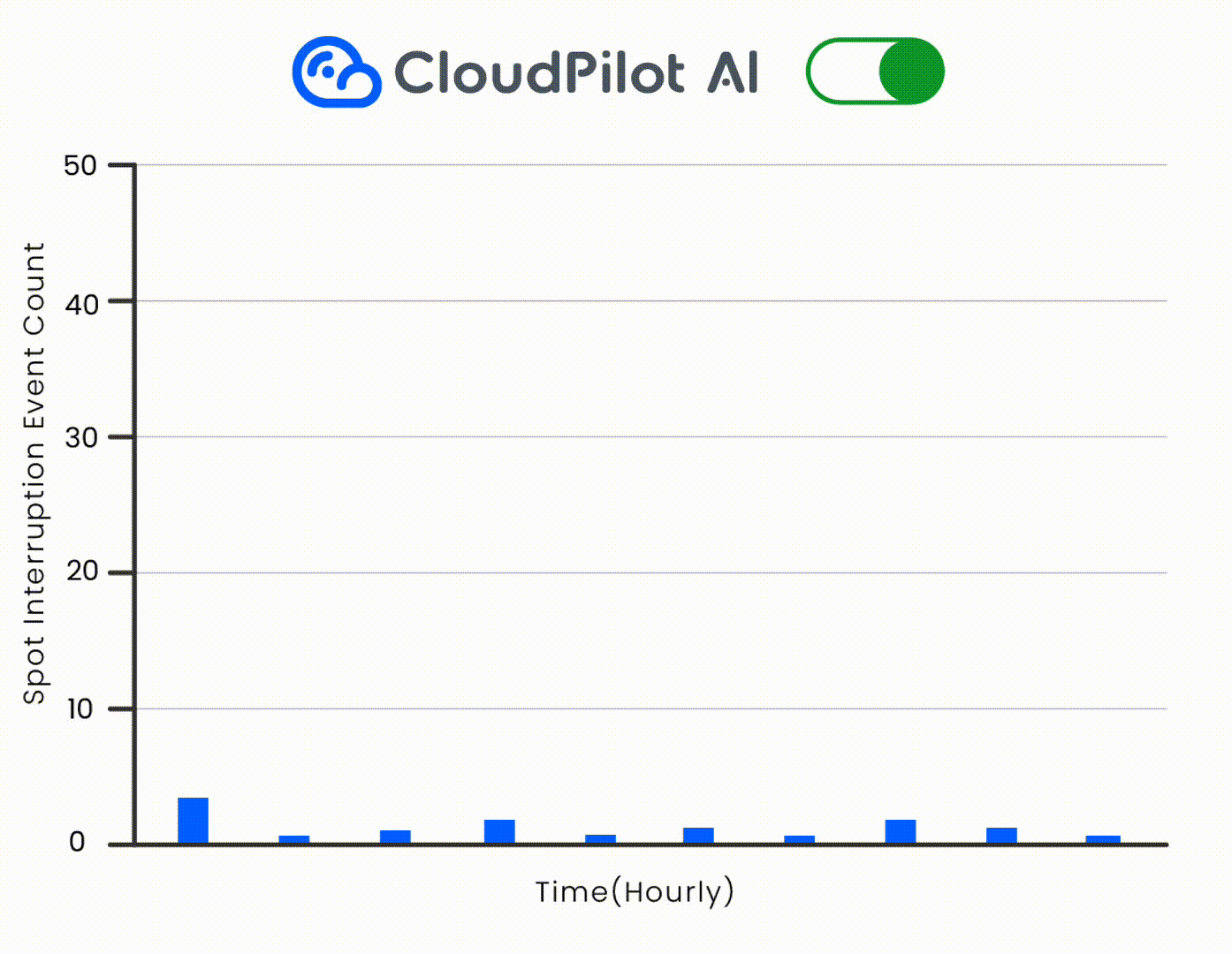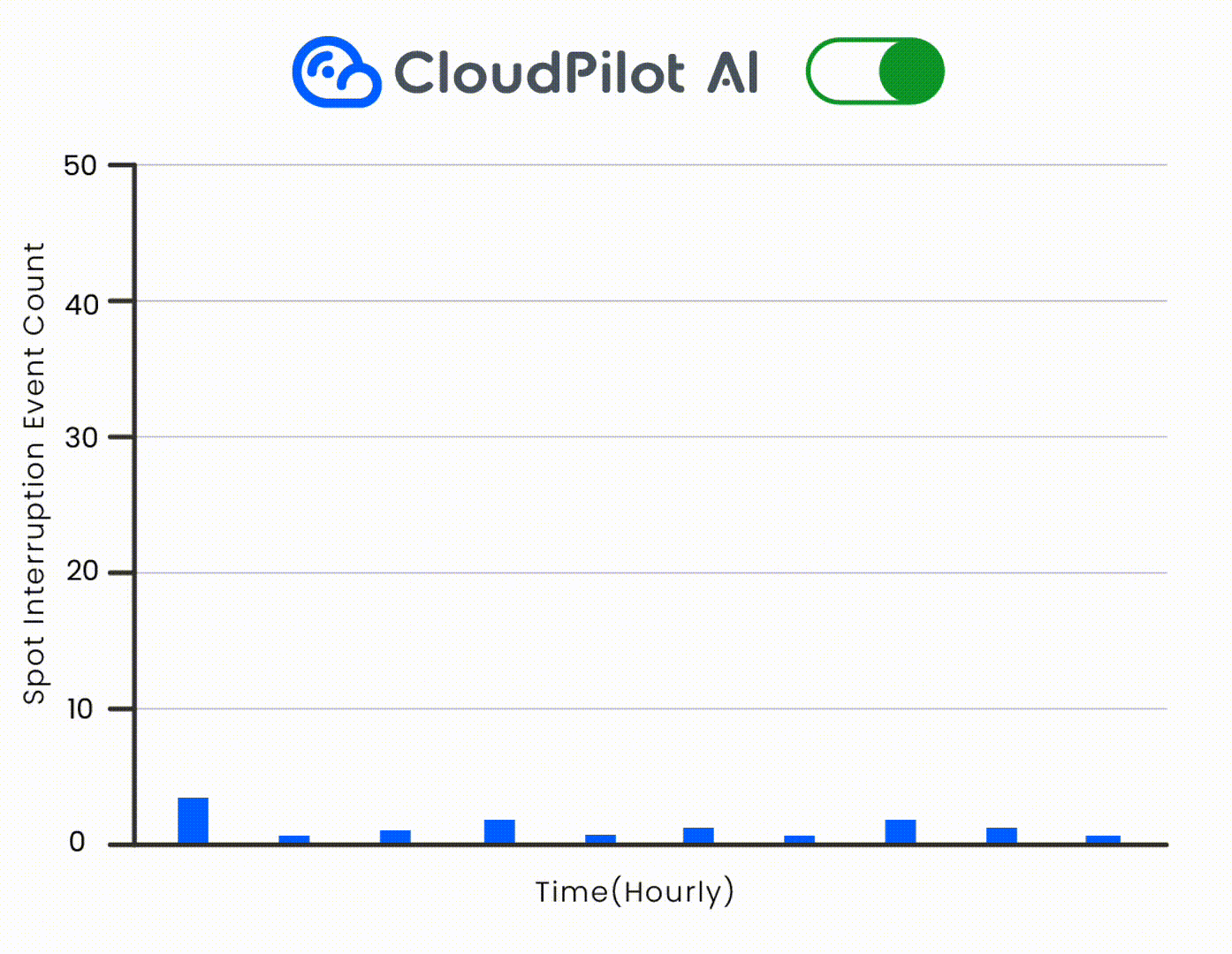
3. Understanding Pod Affinity and Anti-Affinity
These features control how pods are co-located (or not) on the same node or zone. They are powerful — but misuse leads to cost inefficiencies.
Pod Affinity
Encourages pods to run together on the same node or topology domain. Good for tightly coupled apps (e.g., microservices with local communication needs).
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: my-service
topologyKey: "kubernetes.io/hostname"
Use Case: Run app frontends and their sidecars on the same node to reduce latency.
Pod Anti-Affinity
Ensures pods run on separate nodes or zones. Useful for redundancy and high availability.
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: my-service
topologyKey: "kubernetes.io/hostname"
🚨 Caution: Overuse leads to low node utilization, which increases cost.
Best Practice
- Use
preferredDuringSchedulingIgnoredDuringExecutioninstead ofrequired...unless availability is critical. - Always pair with realistic
topologyKeyvalues like:"kubernetes.io/hostname"(per node)"topology.kubernetes.io/zone"(per AZ)
4. Topology Awareness: Cost vs. Resilience
High availability is critical — but it has a price. Spreading replicas across zones or nodes is necessary for resilience, but excessive spreading leads to poor packing.
In many scenarios, topologySpreadConstraints can replace simple podAntiAffinity rules, offering more granular and tunable control. However, for precise co-location or anti-co-location across specific pods, podAffinity/podAntiAffinity is still necessary.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: "ScheduleAnyway"
labelSelector:
matchLabels:
app: my-service
maxSkew: Max difference in pod count between topology domains.topologyKey: Domain to spread across (e.g., node, zone).whenUnsatisfiable:"DoNotSchedule": Fail pod scheduling if constraint isn't met."ScheduleAnyway": Prefer spreading, but don't block scheduling.
Tips:
- Set
maxSkewandwhenUnsatisfiableparameters intopologySpreadConstraintsto relax strict distribution. - Use zonal spreading only for stateless services where it's justified.
🏷️ Tag stateful or sensitive workloads for higher resilience; leave the rest optimized for cost.
5. Proactive Node Management and Consolidation
One of the most overlooked sources of AWS overspend is underutilized or idle EC2 nodes—especially after traffic drops or batch jobs complete. These nodes often linger in the cluster, consuming resources and racking up unnecessary costs.
While Kubernetes provides basic tools like the Cluster Autoscaler, and Karpenter supports time-based TTLs, truly intelligent consolidation requires deeper visibility and predictive automation.
Best Practices for Node Lifecycle Optimization:
- Set short TTLs for empty nodes using tools like Karpenter. This ensures nodes are terminated quickly after all pods are drained.
- Enable Karpenter's consolidation controller to remove underutilized nodes proactively based on bin-packing improvements
- Leverage CloudPilot AI for real-time, cost-aware consolidation
How CloudPilot AI Enhances Consolidation
CloudPilot AI goes beyond simple threshold-based triggers by offering deep observability and predictive scheduling intelligence. It continuously monitors your cluster’s resource utilization patterns and performs:
- Real-time detection of overprovisioned nodes based on actual CPU/memory usage, not just allocation
- Workload-aware consolidation that considers affinity, pod disruption budgets, and Spot instance stability
- Safe and cost-optimized node retirement, including migration of workloads to cheaper instance types or more densely packed nodes
- Insights on potential savings before actions are taken, helping teams stay in control
6. Understanding nodeSelector, nodeAffinity, and Tolerations
Kubernetes provides multiple ways to influence where pods get scheduled. While affinity and topologySpreadConstraints help with pod-to-pod placement, these mechanisms deal with pod-to-node constraints:
| Feature | Purpose | Flexibility | Typical Use Case |
|---|---|---|---|
nodeSelector | Hard requirement (simple match) | ❌ Rigid | Run on a specific instance type or AZ |
nodeAffinity | Hard/soft preference (label-based) | ✅ Flexible | Prefer nodes with specific capabilities |
tolerations | Tolerate taints on nodes | ✅ Required when scheduling on tainted nodes |
nodeSelector: Simple but Limited
nodeSelector is the simplest way to tell Kubernetes a pod must run on nodes with specific labels.
nodeSelector:
instance-type: c6a.large
It's easy to use, but you must match exactly — no OR/IN operators. Use it for fixed constraints like dev/test separation or AZ pinning.
nodeAffinity: Advanced Label Matching
nodeAffinity is a more expressive, preferred alternative to nodeSelector. It supports logical operators, preference weighting, and scheduling behavior control.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: instance-type
operator: In
values: ["c6a.large", "m6a.large"]
It can use In, NotIn, Exists, DoesNotExist and supports required (hard) and preferred (soft) rules
🔁 Combine with Spot/On-Demand pools by labeling nodes accordingly.
tolerations: Scheduling on Tainted Nodes
Taints prevent pods from running on certain nodes—unless they have a matching toleration.
This is essential when using Spot Instances or isolating GPU nodes, as those nodes are often tainted.
tolerations:
- key: "k8s.amazonaws.com/lifecycle"
operator: "Equal"
value: "Ec2Spot"
effect: "NoSchedule"
⚠️ Without the right toleration, the pod won’t be scheduled on tainted nodes.
Recommended Combinations
| Use Case | Strategy |
|---|---|
| Schedule only on Spot nodes | nodeSelector or nodeAffinity + toleration for Spot taint |
| Prefer high-memory instances | preferredDuringSchedulingIgnoredDuringExecution in nodeAffinity |
| Hard requirement for AZ or zone | requiredDuringSchedulingIgnoredDuringExecution in nodeAffinity |
| Avoid tainted GPU nodes by default | Don't define tolerations unless GPU needed |
💡 Pro tip: Label your nodes clearly (e.g., workload-type=stateless, lifecycle=spot) and use a combination of nodeAffinity and tolerations to direct traffic intelligently without over-constraining the scheduler.
Conclusion: Scheduling Is Your Hidden Cost Lever
Smart Kubernetes scheduling isn't just a performance strategy — it's a cost control mechanism. With the right configurations, you can:
- Maximize Spot savings
- Improve bin-packing efficiency
- Minimize resource waste
- Reduce reliance on expensive On-Demand nodes
Whether you're managing hundreds of nodes or just starting out with EKS, platforms like CloudPilot AI give you the technical edge to optimize cost without sacrificing stability.








