
Apache Sparkは大規模データ分析や機械学習を支えていますが、ワークロードが指数関数的に増加するにつれ、従来の静的リソース割り当ては、アイドル状態のExecutorや最適でないインスタンス選択により30〜50%のリソース浪費につながります。
この問題を解決するため、組織はKubernetes ネイティブなオートスケーラーであるKarpenterを採用し、以下の方法でコスト効率を大幅に向上させています:
- インテリジェントなスケジューリング – ポッドのリソース要求を動的に分析し、最適なインスタンスミックス(例:Spotインスタンス、高効率マシン)を選択します。
- 迅速なオートスケーリング – ジョブ開始時に40〜45秒以内にノードをプロビジョニングし、完了時に自動的にリソースを回収します。
- リソース統合 – 断片化した小さなリソース要求を大きなノードに集約し、利用率を85%以上に向上させます。
オンデマンドでコスト最適化されたインフラストラクチャスケーリングを可能にすることで、KarpenterはSparkユーザーがパフォーマンスを最大化しながらクラウドコストを最小化するのを支援します。
なぜKarpenterなのか?
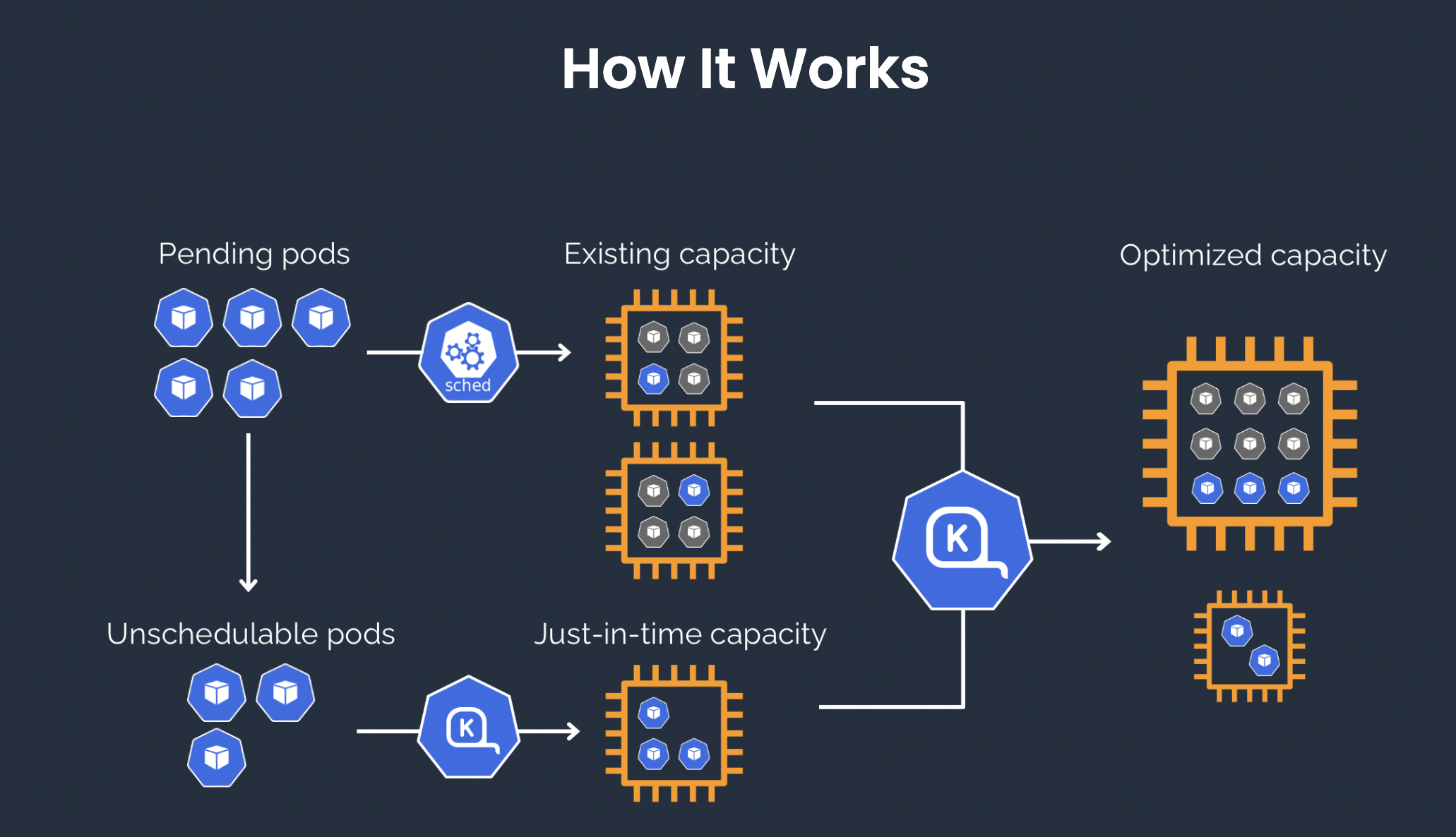
KarpenterはKubernetes向けのインテリジェントなオートスケーラーで、リソース効率を最大化しスケジューリングの遅延を減らすように設計されています。保留中のポッドを即座に検出して対応し、最適なノードタイプを選択し、インスタンスを自動的にプロビジョニングまたは終了します。わずか40〜45秒の応答時間で、KarpenterはCluster Autoscalerの分単位のスケーリングよりも大幅に高速です。
Sparkのようなバッチ処理ワークロード向けに設計されたKarpenterは、Executorノードプールのオンデマンドスケーリングを可能にし、Spotインスタンスを活用して最もコスト効率の高いマシンタイプを選択します。これにより、断片化したリソースを集約してクラスター利用率と効率を最大化しながら、90%以上のクラウドコスト削減が実現します。
Karpenterを使用したSparkコストの最適化
1. クラスターの作成
さまざまなKarpenterの実装を探索できます。このブログではAWSに焦点を当てます。

1.1 Terraformを使用したクラスターの作成
Terraformを使用してクラウドにKubernetesクラスターを作成するには、次のコマンドを入力します:
aws configure
git clone https://github.com/cloudpilot-ai/examples.git
cd examples/clusters/eks-spot
terraform init
terraform apply --auto-approve
クラスター kubeconfig を取得します。
export KUBECONFIG=~/.kube/demo
aws eks update-kubeconfig --name cluster-demonstration
1.2 クラスターのステータス確認
kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-xx-xx.us-east-2.compute.internal Ready <none> 12m v1.32.1-eks-5d632ec
ip-10-0-xx-xx.us-east-2.compute.internal Ready <none> 12m v1.32.1-eks-5d632ec
2. Spark Operatorのデプロイ
Spark OperatorはKubernetesクラスター内でのSparkジョブのライフサイクルの自動デプロイと管理を可能にします。
2.1 Spark-Operatorのインストール
# Add the Helm repository
helm repo add spark-operator https://kubeflow.github.io/spark-operator
helm repo update
# Install the operator into the spark-operator namespace and wait for deployments to be ready
helm install spark-operator spark-operator/spark-operator \
--namespace spark-operator --create-namespace --wait
注:Spark History Serverもインストールする必要がありますが、ここでは個別にリストアップしていません。
2.2 Sparkのテスト
# Create an example application in the default namespace
kubectl apply -f https://raw.githubusercontent.com/kubeflow/spark-operator/refs/heads/master/examples/spark-pi.yaml
# Get the status of the application
kubectl get sparkapp spark-pi
3. Karpenter(karpenter-provider-aws)のデプロイ
Karpenterのデプロイ方法についてはドキュメントを参照してください。
3.1 環境変数の設定:
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.3.1"
export K8S_VERSION="1.32"
export AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
export CLUSTER_NAME="${USER}-karpenter-demo"
export AWS_DEFAULT_REGION="us-west-2"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT="$(mktemp)"
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
3.2 Karpenterのインストール
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
3.3 NodePool/EC2NodeClassの作成
また、nodepool を使用してインスタンスファミリーを指定し、異なる仕様の希望するインスタンスタイプをスケジュールすることもできます(以下に示すとおり)。
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h # 30 * 24h = 720h
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@${ALIAS_VERSION}"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
4. Sparkジョブの自動スケーリングのテスト
4.1 Spark-Piの変更
コスト削減と安定性を確保するため、ドライバーはオンデマンドインスタンスで実行し、エグゼキュータはスポットインスタンスで実行します。その理由は以下の通りです:
1. ドライバーの重要性と安定性の要件
ドライバーはSparkジョブの中核です。ジョブ全体を調整し、エグゼキュータにタスクを割り当て、タスクの実行を監視し、結果を収集します。
ドライバーをスポットインスタンスで実行すると、インスタンスが中断された場合にジョブが失敗する可能性があります。スポットインスタンスはいつでも回収される可能性があるため、ドライバーは安定している必要があります。ジョブの失敗を避けるため、ドライバーは通常、より安定したオンデマンドインスタンスにデプロイされます。
2. エグゼキュータの耐障害性と柔軟性
エグゼキュータは実際の計算タスクを実行し、ジョブ実行中に動的に開始または停止することができます。
スポットインスタンスは中断のリスクが高いですが、オンデマンドインスタンスよりもコスト効率が高いことが多く、計算集約型タスクに理想的です。
スポットインスタンス上のエグゼキュータが終了した場合、Sparkは自動的にタスクを別のエグゼキュータに再スケジュールします。この耐障害性により、一部のスポットインスタンスが中断されてもジョブは継続されます。
ノードアフィニティポリシーを使用することで、ドライバーとエグゼキュータに対して差別化されたノードの弾力性とスケジューリングを実現できます。
spec:
arguments:
- "5000"
deps: {}
driver:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/capacity-type
operator: NotIn
values:
- spot
cores: 1
labels:
version: 3.5.3
memory: 512m
serviceAccount: spark-operator-spark
executor:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
cores: 1
instances: 20
labels:
version: 3.5.3
memory: 512m
4.2 Karpenterでノード作成状況を確認する
kubectl get nodeclaims
NAME TYPE ZONE NODE READY AGE
cloudpilot-general-2nfw7 m7a.2xlarge us-east-2c ip-10-0-xx-xx.us-east-2.compute.internal True 20m
cloudpilot-general-cqz29 m6a.4xlarge us-east-2b ip-10-0-xx-xx.us-east-2.compute.internal True 23m
4.3 Sparkジョブの完了を待つ
kubectl get sparkapplications spark-pi
NAME STATUS ATTEMPTS START FINISH AGE
spark-pi COMPLETED 1 2025-03-06T10:23:14Z 2025-03-06T10:25:18Z 45m
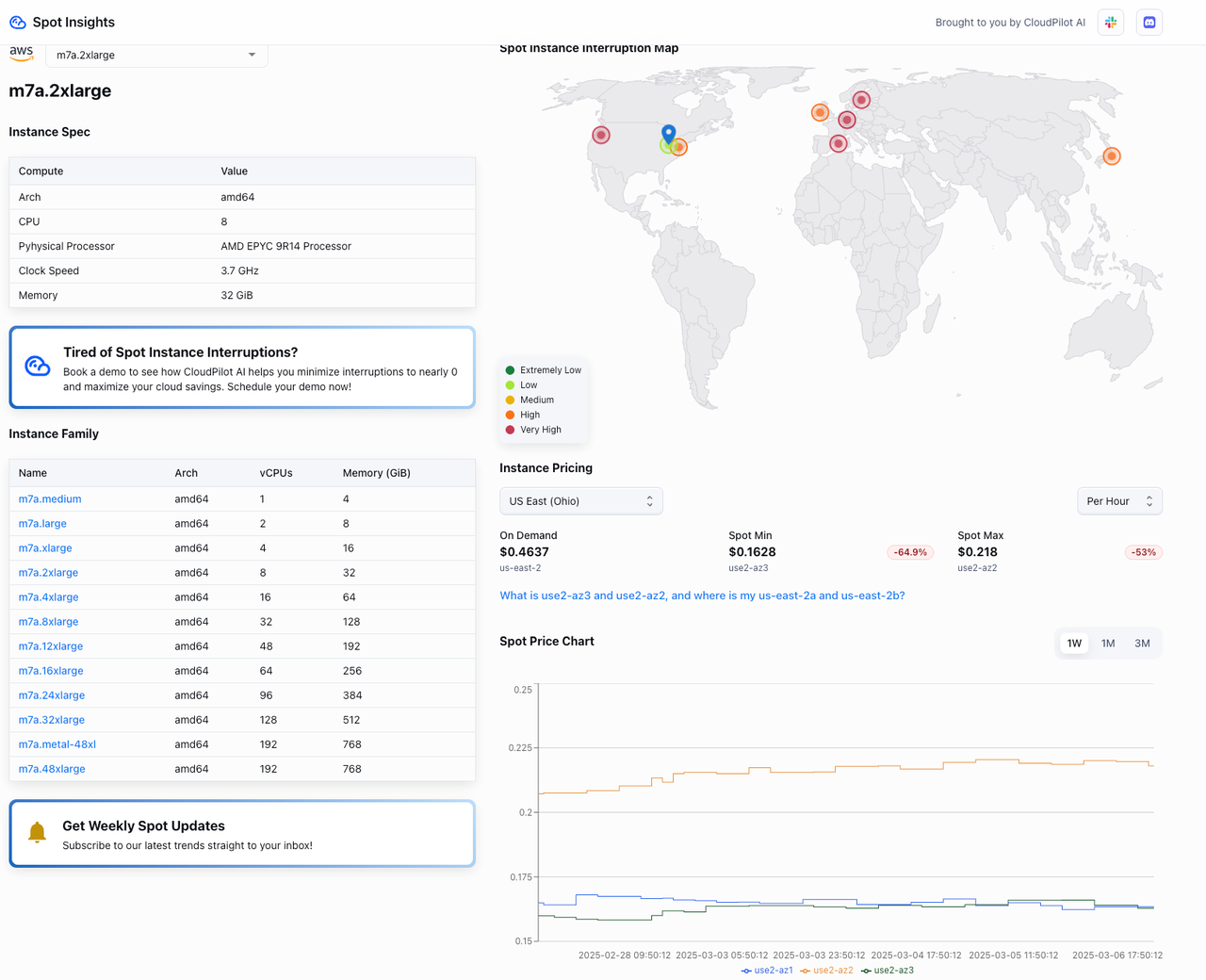
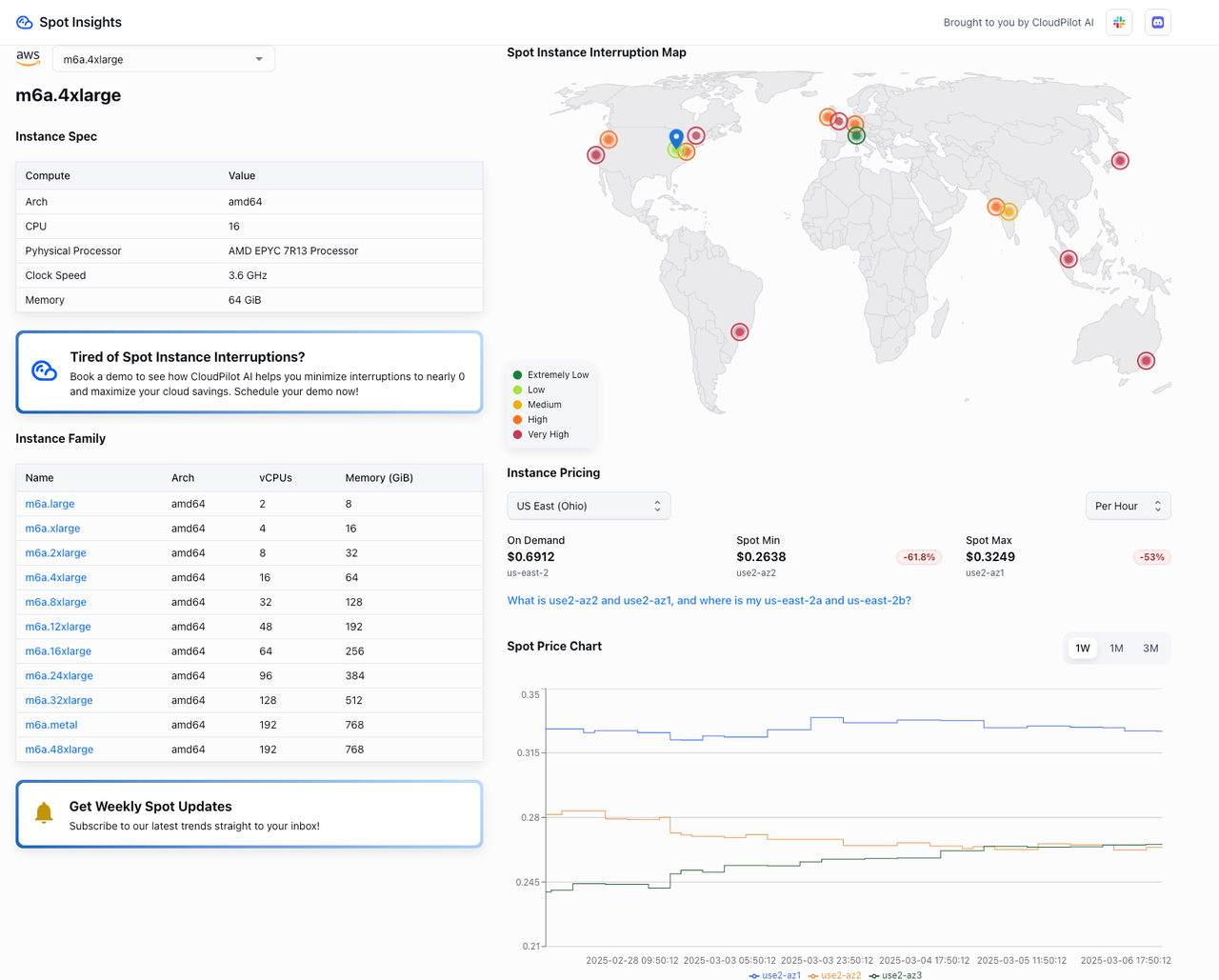
4.4 インスタンスのコスト消費
このSparkジョブでは、Karpenterがエグゼキューターのリソース要件に基づいて、2つのSpotインスタンスノード(タイプ:m7a.2xlarge/m6a.4xlarge)を動的にプロビジョニングしました。ジョブが完了すると、Karpenterは自動的にノードを回収し、リソースがアイドル状態のまま残らないようにしました。
比較から得られた内訳は以下の通りです:
- スポットインスタンスのコスト: オンデマンドインスタンスのわずか10〜40%のコスト(以下参照)。
- 全体的なコスト比較: 従来のCluster Autoscalerソリューションと比較して、Karpenterのインスタンス選択アルゴリズムと断片化されたリソースの集約により、コストを80%以上削減しました。
- 長期サブスクリプションの場合: 固定リソースが使用されるシナリオでは、Karpenterの弾力的なアーキテクチャに切り替えることでアイドル状態のリソースを排除し、長期的なコストを40〜60%削減する可能性があります。
以下の画像は、m7a.2xlarge と m6a.4xlarge のリアルタイム料金を表示しています。これらは Spot Insights から取得されており、AWSスポットインスタンスの価格と中断率を提供するツールです。ぜひご確認ください!
5. (オプション)Sparkジョブの削除
kubectl delete -f https://raw.githubusercontent.com/kubeflow/spark-operator/refs/heads/master/examples/spark-pi.yaml
6. (オプション)Karpenterのアンインストール
helm uninstall karpenter --namespace karpenter-system
kubectl delete ns karpenter-system
結論
このブログでは、SparkジョブとKarpenterを組み合わせてAWS Spotインスタンスを動的にスケジュールし、90%以上の大幅なコスト削減を達成する方法を紹介しています。
クラスターのセットアップ、Spark Operatorのデプロイ、Karpenterの設定、Sparkジョブの自動スケーリングとコスト最適化まで、プロセス全体を解説しています。
詳細なデプロイ手順と設定例を提供することで、Kubernetes環境内でKarpenterの自動スケーリング機能を活用してリソース使用率を最大化し、計算コストを効果的に削減する方法を示しています。これにより、Sparkを大量に使用する組織にとって非常に効率的でコスト効果の高いクラウドコンピューティングソリューションを提供します。









