

Kubernetes 1.27ではIn-Place Podリサイジング(In-Place Pod垂直スケーリングとも呼ばれる)が導入されました。しかし、これは正確には何でしょうか?そしてあなたにとって何を意味するのでしょうか?
Kubernetes v1.27でアルファ機能として導入されたIn-Place Podリサイジングは、従来のPod全体を再起動する必要なく、実行中のコンテナのCPUとメモリリソースを動的に調整することを可能にします。
この機能はv1.27以降利用可能でしたが、フィーチャーゲートの背後に残されていたため、デフォルトでは無効であり、手動での有効化が必要でした。Kubernetesのフィーチャーゲートは実験的または開発中の機能のトグルとして機能し、クラスター管理者が新機能がまだ改良されテストされている間にそれらを選択できるようにします。
執筆時点では、In-Place PodリサイジングはKubernetes v1.33でベータステータスに昇格し、デフォルトで有効になります。このアルファからベータへの進展は、機能が大幅に成熟し、APIが広範な採用に十分安定したことを示しています。
この記事では、In-Place Podリサイジングの仕組みを深く掘り下げ、ハンズオンデモを通じてKubernetesの最新機能を直接体験し、ワークロードとインフラコストへの実用的な影響を探ります。
Kubernetesスケーリング手法の簡単な歴史
将来を見据える前に、Kubernetesでのワークロードスケーリングが従来どのように機能していたかを振り返る価値があります。初期の頃、リソース割り当ては主に手動で行われていました。デプロイ時にリクエストとリミットを定義し、それらの値はPodのライフサイクルを通じて固定されたままでした。
より多くのリソースが必要な場合は、デプロイメント設定を更新し、Kubernetesが古いPodを終了して更新されたリソース仕様で新しいPodを作成するのを待つ必要がありました。
このアプローチはシンプルなステートレスアプリケーションには十分機能しましたが、Kubernetesの採用が拡大するにつれて、その上で実行されるワークロードの複雑さも増しました。より動的なリソース管理の必要性が明らかになりました。これにより、2015年11月のKubernetes 1.1でHorizontal Pod Autoscaler(HPA)が導入されました。HPAはCPUとメモリ使用量に基づいてワークロードをより動的にスケールアウトするのに役立つように設計されました。
Kubernetes 1.8に進むと、Vertical Pod Autoscaler(VPA)が既存のPodに割り当てられたCPUとメモリを動的にリサイズする方法として導入されました。HPAがインスタンスを追加して水平方向にスケールする一方、VPAは個々のPodのリソース割り当てを調整して垂直方向にスケールしました。
これらすべてが進行している間、2019年にMicrosoftとRed Hatの共同の取り組みにより、Kubernetes Event-driven Autoscaling、略してKEDAが作成されました。
当初はOpenShift上のAzure関数をより良くサポートすることを目的としていましたが、KEDAのオープンソースの性質により、コミュニティはすぐにその使用例を当初の範囲をはるかに超えて拡大しました。
KEDAは外部メトリクスとイベントに基づくスケーリングを可能にし、従来のリソースベースのスケーリングと現代のアプリケーションの複雑なイベント駆動型の性質の間のギャップを埋めます。
では、これらすべてのスケーリング方法が存在するなら、水平スケーリングのためのHPA、垂直スケーリングのためのVPA、イベント駆動スケーリングのためのKEDAがあるのに、なぜIn-Place Podリサイジングが存在するのでしょうか?既存のエコシステムでは対応できない、どのような問題を解決するのでしょうか?
In-Place Podリサイジングとは?
簡単に言えば、In-Place Pod垂直スケーリングは、Podを再起動せずに実行中のコンテナのCPUとメモリリソースを変更することを可能にします。これは小さな改善のように聞こえるかもしれませんが、Kubernetesのリソース管理が初期から抱えていた根本的な制限に対処するものです。
Kubernetesにおける従来の垂直スケーリングでは、「取り外して交換する」というアプローチが必要でした。Podのリソースを調整する必要がある場合、手動更新やPodオートスケーラーのいずれかを通じて、Kubernetesは既存のPodを終了し、更新されたリソース仕様で新しいPodを作成していました。この処理は機能的ではありますが、特定のワークロードにとって問題となる可能性のある、いくつかの破壊的な副作用をもたらしていました。
最も直接的な影響はTCP接続の中断でした。Podが再起動すると、既存のすべてのネットワーク接続が切断され、クライアントは再接続を強いられ、データストアとの安定した接続を維持する必要があるステートフルおよびステートレスワークロードの処理中リクエストが失われる可能性がありました。
In-placeリサイジングは、コンテナプロセスを終了せずにコンテナランタイムがリソース制限とリクエストを調整できるようにすることで、この中断を排除します。
In-Place Podリサイジングはどのように機能するのか?
In-Place Podリサイジング(In-Place Pod垂直スケーリング)の仕組みを理解するために、2019年に遡り、GitHubのissue #1287で最初の機能強化提案がオープンされたときを振り返ることができます。
その核心において、インプレースリサイジングは、望ましい状態と現在保有している状態の明確な区別を導入します。Pod.Spec.Containers[i].Resourcesフィールドは、Podリソースの望ましい状態を表すようになりました。これは目標設定と考えてください。一方、新しいPod.Status.ContainerStatuses [i].Resourcesフィールドは、実行中のコンテナに現在割り当てられている実際のリソースを示し、ノード上で実際に起こっていることを反映します。
この構造的変更により、より洗練されたリソース管理ワークフローが可能になります。Podをリサイズしたい場合、もはやPod仕様を直接変更することはありません。代わりに、特定のリソース関連フィールドのみを受け付ける新しい/resizeサブリソースと対話します。この専用エンドポイントにより、リソースの変更が適切な検証を経て、他のPod操作と干渉しないことが保証されます。
また、Pod.Status.ContainerStatuses [i].AllocatedResourcesを通じて割り当てられたリソースの概念も導入されました。Kubeletが最初にPodを受け入れるとき、またはリサイズリクエストを処理するときに、これらのリソース要件をローカルにキャッシュします。このキャッシュされた状態は、コンテナが起動または再起動されるときにコンテナランタイムの信頼できる情報源となり、リサイズライフサイクル全体で一貫性を保証します。
以下は元のKEPからの図で、このオーケストレーションがどのように行われるかの簡略化されたワークフローを示しています:
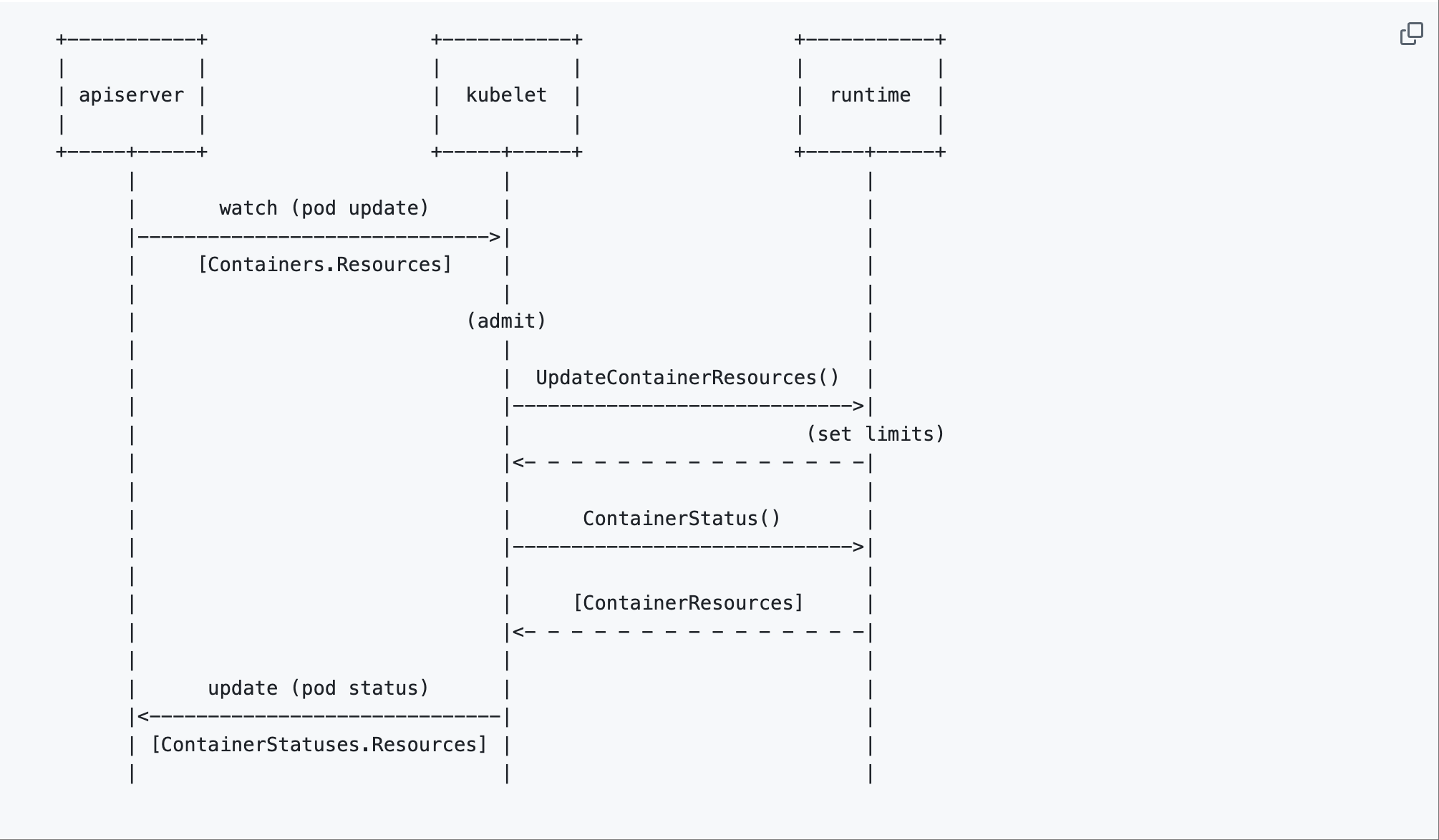
出典:Kubernetes Enhancementsリポジトリ
図から分かること:
- APIサーバーがリサイズリクエストを受信します
- Kubeletが Pod の更新を監視し、コンテナランタイムの
UpdateContainerResources()APIを呼び出して新しい制限を設定します - ランタイムは
ContainerStatus()を通じて実際のリソース状態を報告します。
リサイズ操作の進行状況を追跡するために、システムは2つの新しいPod条件を使用します。PodResizePendingは、リサイズが要求されたがまだKubeletによって処理されていないことを示し、PodResizeInProgressは、リサイズが積極的に適用されていることを示します。
これらの条件はリサイズのライフサイクルの可視性を提供し、オペレーターがリソース移行中に何が起きているかを理解するのに役立ちます。
Podのインプレースリサイジングのユースケース
内部の仕組みを理解したところで、これが今後のワークロードにどのように適用されるか気になっていることでしょう。いくつかのユースケースを紹介します。
機械学習
機械学習ワークロードは、インプレースリサイジングの最も説得力のあるケースかもしれません。典型的なML(機械学習)パイプラインを考えてみましょう。モデルトレーニングジョブは、最小限のメモリしか必要としないCPU集約型のデータ前処理から始まります。トレーニングが実際のモデル計算フェーズに進むと、ワークロードはメモリ集約型になり、CPU要件は減少する可能性があります。
従来のスケーリングでは、リソース割り当てを調整するためにPodを終了させ、何時間ものトレーニング進捗を失うことになります。インプレースリサイジングを使用すると、同じPodが前処理中のCPU最適化構成からトレーニング中のメモリ最適化セットアップへ移行し、その後モデル提供のためのバランスの取れた構成にスケールダウンすることができます。
リソース変更中のデータベース接続の維持
インプレースリサイジングがなければ、追加メモリを要求するとデータベース接続が切断され、ジョブは接続を再確立し、トランザクションコンテキストを失う可能性があります。インプレースリサイジングを使用すると、同じPodが処理中に追加メモリを要求しながらデータベース接続を維持できます。
コスト最適化
インプレースリサイジングが測定可能な価値をもたらすのはコスト削減です。従来のリソース管理では、チームがアプリケーションライフサイクル全体でピーク時のリソース使用量を考慮する必要があるため、過剰なプロビジョニングにつながることがよくあります。ピーク処理時に4GBのメモリが必要だが、通常状態では1GBしか必要としないPodは、通常、そのライフサイクル全体を通じて4GBが割り当てられます。
インプレースPodリサイジングの実践
基本的な概念を理解したところで、ローカルでインプレースPodリサイジングをテストする方法を紹介します。
前提条件
このガイドに沿って進めるには、マシンに以下のツールが設定されている必要があります:
ステップ1:クラスター構成を作成する
KinDでは、有効にしたいKubernetesのバージョンとフィーチャーゲートを構成ファイルで定義できます。
ターミナルで次のコマンドを実行します:
cat <<EOF > cluster.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: inplace
featureGates:
"InPlacePodVerticalScaling": true
nodes:
- role: control-plane
image: kindest/node:v1.33.1@sha256:050072256b9a903bd914c0b2866828150cb229cea0efe5892e2b644d5dd3b34f
- role: worker
image: kindest/node:v1.33.1@sha256:050072256b9a903bd914c0b2866828150cb229cea0efe5892e2b644d5dd3b34f
EOF
ここで注意すべき重要な点はfeatureGatesです。ここで有効にする機能ゲートを指定します。この場合、InPlacePodVerticalScalingとノードイメージv1.33.1が指定されています。これはGitHubのkindリリースページから取得されました。
次のコマンドを実行してクラスターをプロビジョニングします:
kind create cluster --config cluster.yaml
出力は以下のようになるはずです:
ステップ2:テスト用デプロイメントを作成する
まず、リサイズできる簡単なアプリケーションをデプロイします。以下のマニフェストを適用してください:
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
replicas: 1
selector:
matchLabels:
app: app
template:
metadata:
labels:
app: app
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "1Gi"
cpu: 3
requests:
memory: "500Mi"
cpu: 2
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired
- resourceName: memory
restartPolicy: RestartContainer
EOF
resizePolicy設定に注目してください。ここでアプリケーションがリソース変更をどのように処理するかを指定します。CPUについては、restartPolicy: NotRequiredを設定しており、これはコンテナを再起動せずにCPU割り当てを調整できることを意味します。メモリについては、restartPolicy: RestartContainerを指定しており、メモリの変更がコンテナの再起動をトリガーすることを示しています。
この設定は、追加のメモリ割り当てを活用するために再起動が必要なメモリ依存のアプリケーションに特に役立ちます。Javaアプリケーション、ヒープサイズ設定を持つプロセス、またはバッファプール設定を持つデータベースなどは、新しいメモリ制限を適切に利用するために再起動が必要なことが多く、明示的な再起動ポリシーが合理的な選択となります。
ステップ3:初期CPU割り当ての確認
変更を加える前に、コンテナのcgroup設定を調べて現在のCPU割り当てを確認します:
kubectl exec -it $(kubectl get pods -l app=app -o jsonpath='{.items[0].metadata.name}') -- cat /sys/fs/cgroup/cpu.max
上記のコマンドは、コンテナ内の /sys/fs/cgroup/cpu.max を確認します。これは、Linuxカーネルがコンテナが使用できるCPU時間を制御するCPUクォータと期間の設定を公開する場所だからです。
出力には2つの値が表示されます:
- CPUクォータ(コンテナが使用できるCPU時間)
- 期間(そのクォータの時間枠)
これらが組み合わさって、実効的なCPU制限が決まります。
出力は以下のようになります:

ステップ4:インプレースCPUリサイズの実行
ここで、パッチ操作を使用してCPU制限を3コアから4コアに増やします:
kubectl patch deployment app --patch '{
"spec": {
"template": {
"spec": {
"containers": [{
"name": "nginx",
"resources": {
"limits": {
"cpu": "4"
}
}
}]
}
}
}
}'
パッチを適用した後、再度CPU割り当てを確認します:
kubectl exec -it $(kubectl get pods -l app=app -o jsonpath='{.items[0].metadata.name}') -- cat /sys/fs/cgroup/cpu.max
変更がcgroup設定に反映されるまで数秒かかりますが、以下のような出力が表示されるはずです:

最後に、実際に再起動が発生しなかったことを確認するために以下を実行します:
k get pods -o wide
出力は以下のようになります:

インプレーススケーリングの重要な注意点(制約事項)
ソフトウェアの素晴らしい機能には常に制約があるように、インプレースPodリサイズにもいくつかの注意点があります。
コンテナランタイムのサポート
インプレースリサイズには特定のコンテナランタイムのサポートが必要であり、すべてのランタイムが互換性を持つわけではありません。現在、containerd v1.6.9+、CRI-O v1.24.2+、およびPodman v4.0.0+がインプレースリソース更新に必要なAPIをサポートしています。古いバージョンのランタイムを実行している場合は、この機能を利用する前にアップグレードする必要があります。
デフォルトのリサイズ動作
すべての新しいPodは、各コンテナに対して resizePolicy フィールドが自動的に設定されます。このフィールドを明示的に設定しない場合、デフォルトの動作は restartPolicy: NotRequired となり、コンテナは再起動せずにインプレースでのリサイズを試みます。このデフォルト設定はほとんどのアプリケーションで問題なく機能しますが、新しいリソース割り当てを適切に利用するために再起動が必要なコンテナについては、リサイズポリシーを明示的に設定する必要があります。
リソース割り当ての境界
ノードで利用可能な量を超えるリソースをリクエストしても、CPUやメモリの制限を調整する場合でも、Podの退避はトリガーされません。これは、リソースの圧迫によってPodのスケジューリングが変更される可能性がある従来のリソース管理とは異なる動作です。リサイズリクエストは、ノードに十分なリソースが利用可能になるまで単に保留状態のままとなります。
Kubernetesリソース管理にインテリジェンスをもたらす
Kubernetes のOctarine(v1.33)リリースは、コミュニティが革新的な機能を提供することへの取り組みを反映した歓迎すべき進展です。このブログでは、その場でのPodリサイズについて、それが何であるか、なぜ存在するのか、そしてKubernetes環境でどのように使用できるかについて説明しました。
前述のように、Kubernetesのオートスケーリングエコシステムは、Pod、リソース、インフラストラクチャ、外部負荷など、環境の異なるレイヤーに対応するための多くのツールで構成されています。
現在のスケーリング設定がHPAとCluster Autoscalerのみに依存している場合、効率性、回復力、コスト削減の機会を逃している可能性が高いでしょう。CloudPilot AIは、Spotインスタンス管理を自動化し、800種類以上のインスタンスタイプから最適なノードをインテリジェントに選択することで、これらのツールを補完し、チームがよりスマートにスケールし、支出を削減するのを支援します。









