
クラウドネイティブインフラの時代において、Kubernetesはスケーラブルなコンテナ化ワークロードをデプロイするための標準となっています。しかし、企業が弾力的なコンピューティングと自動スケーリングを採用するにつれて、一つの課題がよく浮上します:急騰するAWS請求書です。
ワークロードがAmazon EKS上で実行されている場合、ポッドのスケジューリング方法がコスト効率に大きく影響します。この記事では、パフォーマンスや可用性を損なうことなくAWSコストを削減できるKubernetesスケジューリング戦略を探ります。
スケジューリングがコストに重要な理由
Kubernetesのスケジューリングは、単にワークロードを実行させるだけでなく、どこでどのように実行するかに関わります。 スケジュールされる各ポッドは、クラスターオートスケーラーやKarpenterなどのツールによってプロビジョニングされるEC2インスタンスに変換されます。不適切なスケジューリングは以下を引き起こします:
- 十分に活用されていないインスタンス
- ビンパッキングの非効率性
- オンデマンドノードへの過度の依存
- アンチアフィニティの設定ミスによる無駄なコンピューティングリソース
良いニュースは、スケジューリングの決定に影響を与えることで、コスト最適化されたビンパッキング、より良いスポット使用率、改善されたノードライフサイクル効率を達成できることです。
1. ビンパッキング:効率的なスケジューリングの基盤
Kubernetesはデフォルトでポッドを積極的にビンパッキングしません。デフォルトのスケジューラは、最大密度よりもバランスの取れたリソース割り当てを優先するため、リソース使用の断片化につながる可能性があります。
コスト効率の良いビンパッキングを有効にする方法:
topologySpreadConstraintsは必要な場合にのみ使用してください。過度に使用すると、ポッドが不必要に分散され、容量が無駄になります。podAffinityとpodAntiAffinityは慎重に活用してください。絶対に必要な場合を除き、グローバルなアンチアフィニティは避けてください。consolidationPolicyを使用したKarpenterなどの統合ツールを使用して、使用率の低いノードを積極的に削除してください。
💡 プロのヒント:Karpenterでleast-wasteビンパッキング戦略を使用して、密集したスケジューリングを優先してください。
2. スポットインスタンス:中断を考慮した節約のためのスケジューリング
スポットインスタンスはオンデマンドと比較して最大90%の割引を提供しますが、中断のリスクがあります。スポットを安全に使用するには、戦略的にポッドをスケジュールする必要があります。
主要な戦術:
-
テイントベースのSpotスケジューリング:Spotノードに
NoScheduleテイントを使用して、重要なポッドがそこにスケジュールされるのを防ぎ、許容可能なワークロードには適切なトレレーションを適用します。taints: - key: "k8s.amazonaws.com/lifecycle" value: "Ec2Spot" effect: "NoSchedule" -
複数のスポットキャパシティプール:同時中断を最小限に抑えるために、AZ全体でインスタンスタイプを多様化します。
-
ノードセレクターとアフィニティを使用して、重要でないワークロードをスポットノードにプッシュします。
-
Spot Insightsを使用して、利用可能なゾーン全体のリアルタイムのスポット価格と中断を照会します。
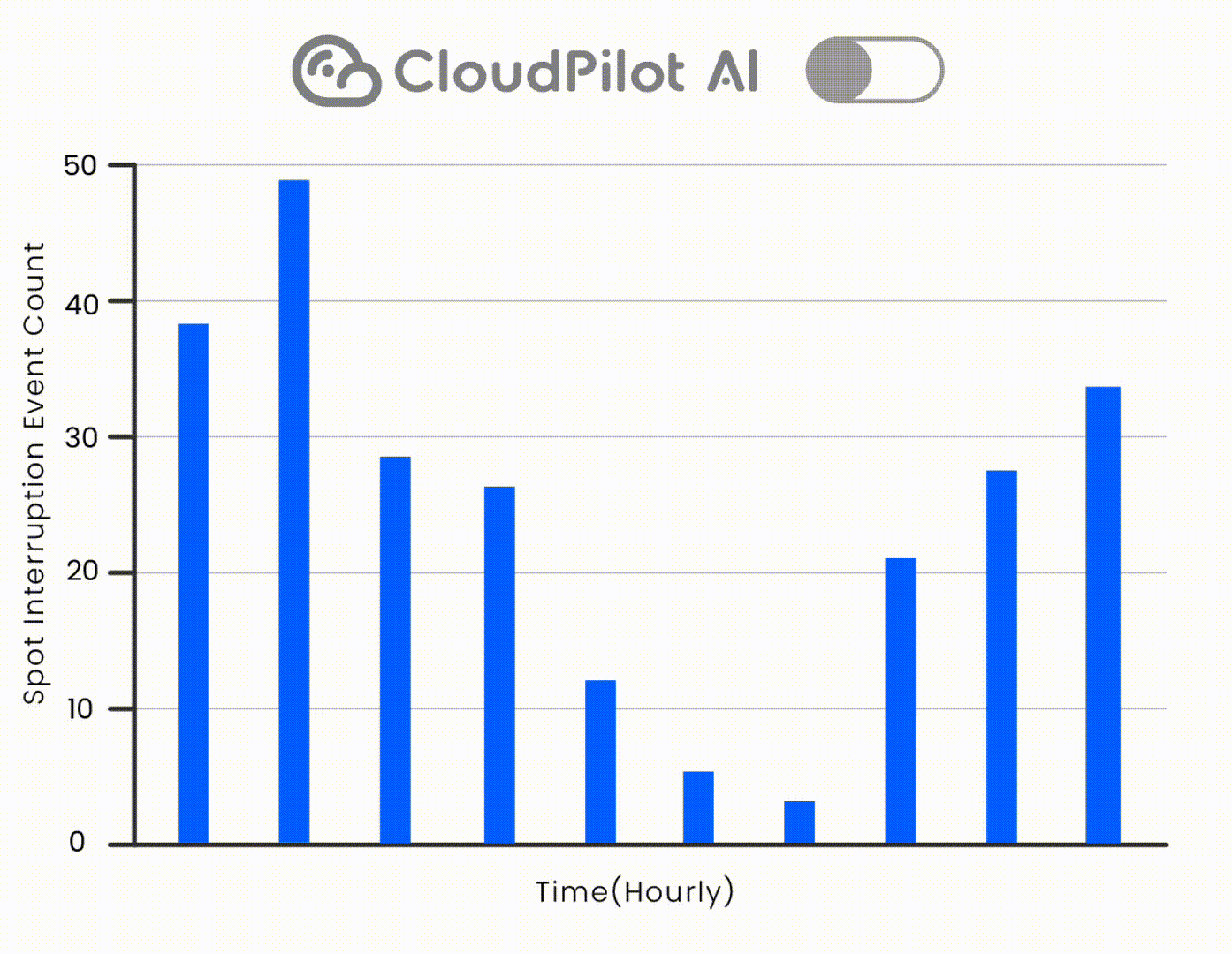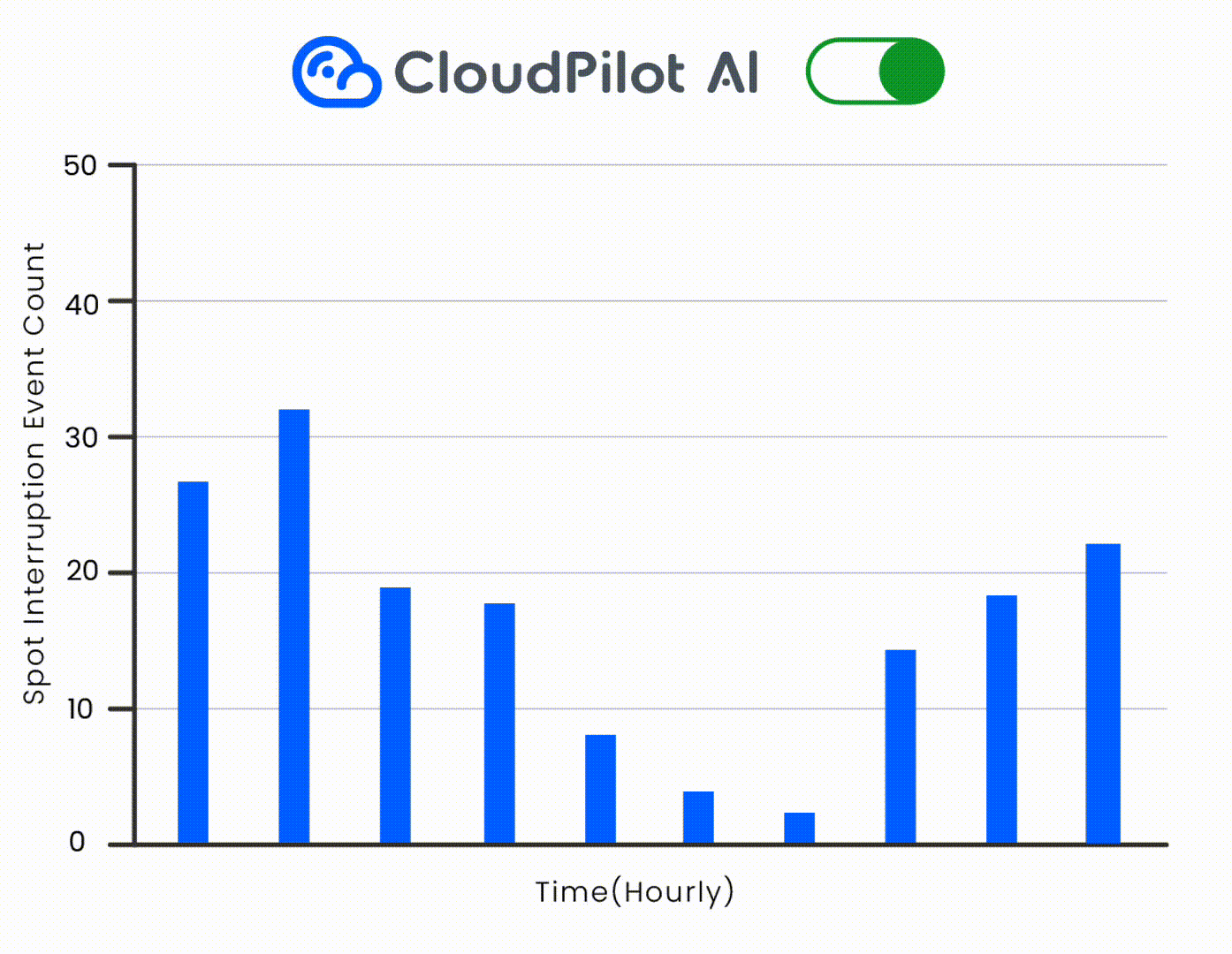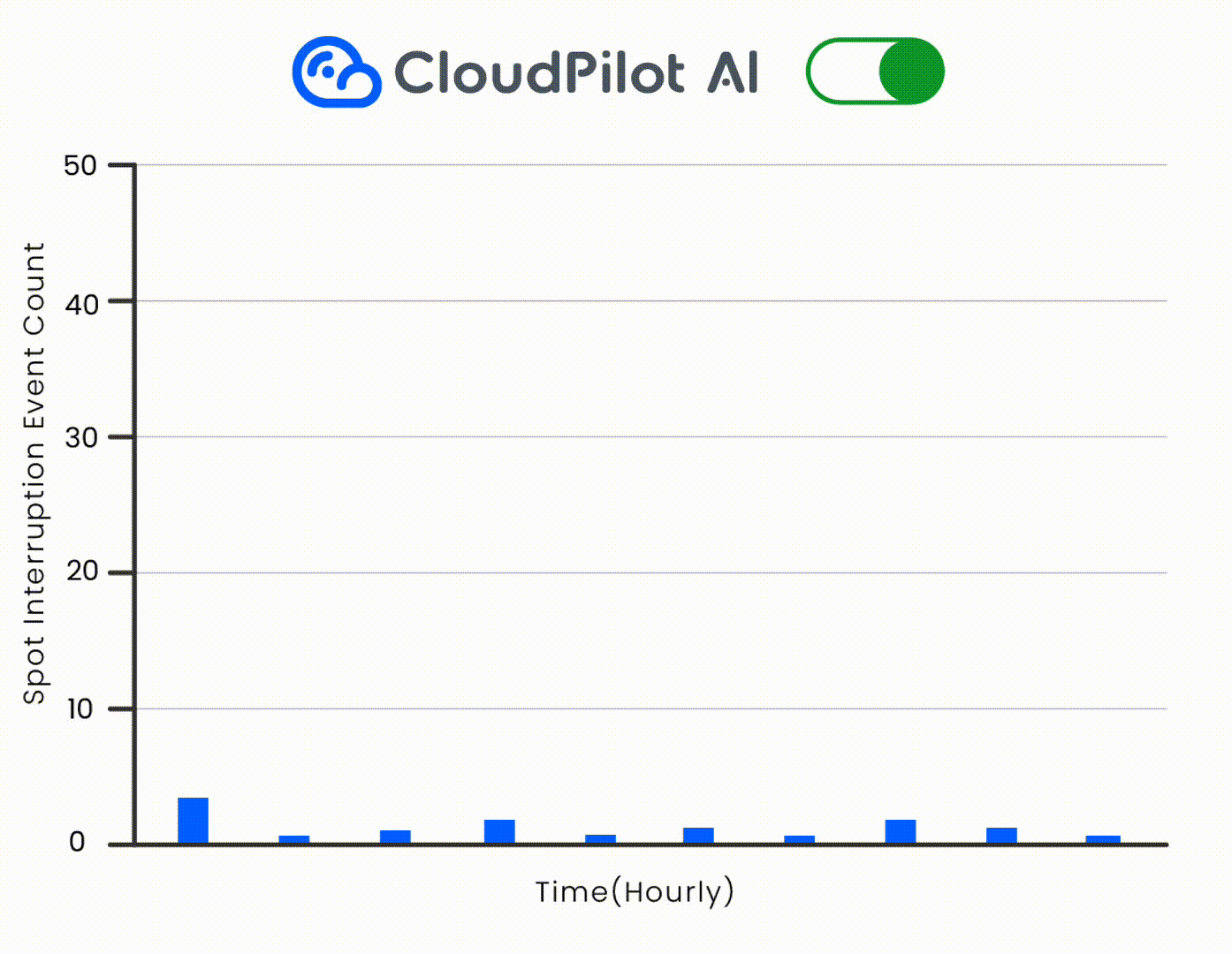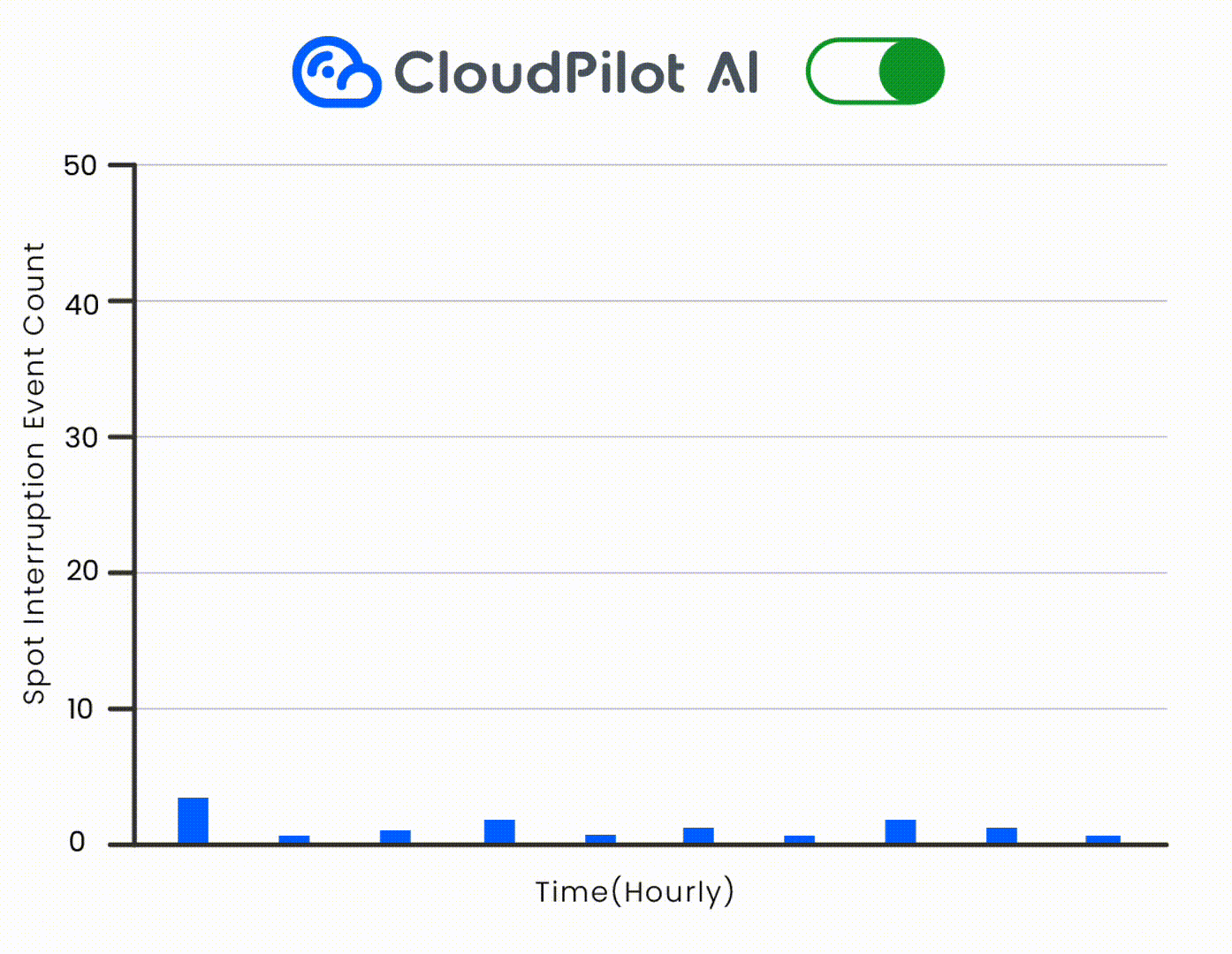
🛡️ これをCloudPilot AIの45分間の中断予測と自動フォールバックと組み合わせて、安全にドレイニングを処理します。
3. ポッドアフィニティとアンチアフィニティの理解
これらの機能は、ポッドが同じノードまたはゾーンに配置される(またはされない)方法を制御します。これらは強力ですが、誤用するとコスト効率が低下します。
ポッドアフィニティ
ポッドが同じノードまたはトポロジードメインで一緒に実行されることを奨励します。密接に結合されたアプリ(例:ローカル通信が必要なマイクロサービス)に適しています。
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: my-service
topologyKey: "kubernetes.io/hostname"
ユースケース:レイテンシーを減らすために、アプリのフロントエンドとそのサイドカーを同じノードで実行します。
ポッドアンチアフィニティ
ポッドが別々のノードまたはゾーンで実行されることを確保します。冗長性と高可用性に役立ちます。
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: my-service
topologyKey: "kubernetes.io/hostname"
🚨 注意:過剰使用するとノードの使用率が低下し、コストが増加します。
ベストプラクティス
- 可用性が重要でない限り、
required...の代わりにpreferredDuringSchedulingIgnoredDuringExecutionを使用してください。 - 常に現実的な
topologyKey値と組み合わせてください:"kubernetes.io/hostname"(ノードごと)"topology.kubernetes.io/zone"(AZごと)
4. トポロジー認識:コストと耐障害性のバランス
高可用性は非常に重要ですが、それには代償が伴います。レプリカをゾーンやノード間に分散させることは耐障害性に必要ですが、過度な分散はリソースの効率的な配置を妨げます。
多くのシナリオでは、topologySpreadConstraintsがシンプルなpodAntiAffinityルールを置き換えることができ、より細かく調整可能な制御を提供します。ただし、特定のポッド間で正確なコロケーションまたはアンチコロケーションを行う場合は、podAffinity/podAntiAffinityが依然として必要です。
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: "ScheduleAnyway"
labelSelector:
matchLabels:
app: my-service
maxSkew:トポロジードメイン間のポッド数の最大差。topologyKey:分散するドメイン(例:ノード、ゾーン)。whenUnsatisfiable:"DoNotSchedule":制約が満たされない場合、ポッドのスケジューリングを失敗させます。"ScheduleAnyway":分散を優先しますが、スケジューリングをブロックしません。
ヒント:
topologySpreadConstraintsでmaxSkewとwhenUnsatisfiableパラメータを設定して、厳密な分散を緩和します。- ゾーン分散は、正当な理由がある場合にのみステートレスサービスに使用してください。
🏷️ ステートフルまたは重要なワークロードには高い耐障害性のためのタグ付けを行い、それ以外はコスト最適化のままにしておきましょう。
5. プロアクティブなノード管理と集約
AWSの過剰支出の最も見落とされがちな原因の一つは、使用率の低いまたはアイドル状態のEC2ノードです—特にトラフィックが減少したりバッチジョブが完了した後も残っているノードです。これらのノードはクラスター内に残り続け、リソースを消費し、不必要なコストを積み上げていきます。
Kubernetesは基本的なツールとしてCluster Autoscalerを提供し、Karpenterは時間ベースのTTLをサポートしていますが、真に賢明な集約には、より深い可視性と予測的な自動化が必要です。
ノードライフサイクル最適化のベストプラクティス:
- Karpenterなどのツールを使用して、空のノードに短いTTLを設定します。これにより、すべてのポッドがドレインされた後、ノードが迅速に終了します。
- Karpenterの集約コントローラを有効にして、ビンパッキングの改善に基づいて使用率の低いノードを積極的に削除します。
- リアルタイムのコスト認識型集約にCloudPilot AIを活用します。
CloudPilot AIによる統合の強化
CloudPilot AIは、単純な閾値ベースのトリガーを超え、深い可観測性と予測スケジューリングインテリジェンスを提供します。クラスターのリソース使用パターンを継続的に監視し、以下を実行します:
- 割り当てだけでなく、実際のCPU/メモリ使用量に基づいたオーバープロビジョニングされたノードのリアルタイム検出
- アフィニティ、ポッド中断バジェット、Spotインスタンスの安定性を考慮したワークロード対応の統合
- より安価なインスタンスタイプやより密に詰め込まれたノードへのワークロードの移行を含む、安全でコスト最適化されたノードの廃止
- アクションが取られる前の潜在的な節約に関する洞察を提供し、チームが制御を維持するのを支援
6. nodeSelector、nodeAffinity、およびTolerationsの理解
Kubernetesは、ポッドがスケジュールされる場所に影響を与える複数の方法を提供しています。アフィニティとtopologySpreadConstraintsはポッド間の配置に役立ちますが、これらのメカニズムはポッドとノード間の制約を扱います:
| 機能 | 目的 | 柔軟性 | 典型的なユースケース |
|---|---|---|---|
nodeSelector | ハード要件(シンプルなマッチ) | ❌ 厳格 | 特定のインスタンスタイプまたはAZで実行 |
nodeAffinity | ハード/ソフト設定(ラベルベース) | ✅ 柔軟 | 特定の機能を持つノードを優先 |
tolerations | ノードのテイントを許容 | ✅ テイント付きノードでのスケジューリング時に必要 |
nodeSelector: シンプルだが制限あり
nodeSelectorは、特定のラベルを持つノードでPodを実行する必要があることをKubernetesに伝える最もシンプルな方法です。
nodeSelector:
instance-type: c6a.large
使い方は簡単ですが、完全一致が必要です — OR/IN演算子は使えません。dev/testの分離やAZ固定のような固定的な制約に使用してください。
nodeAffinity: 高度なラベルマッチング
nodeAffinityは、nodeSelectorよりも表現力が高く、推奨される代替手段です。論理演算子、優先度の重み付け、スケジューリング動作の制御をサポートしています。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: instance-type
operator: In
values: ["c6a.large", "m6a.large"]
In、NotIn、Exists、DoesNotExistを使用でき、必須(ハード)ルールと推奨(ソフト)ルールをサポートします
🔁 ノードに適切にラベル付けすることで、スポット/オンデマンドプールと組み合わせることができます。
tolerations: Taintされたノードへのスケジューリング
Taintは、対応するtolerationを持たない限り、Podが特定のノードで実行されることを防ぎます。
これは、スポットインスタンスやGPUノードを分離する場合に不可欠です。これらのノードは多くの場合テイントされています。
tolerations:
- key: "k8s.amazonaws.com/lifecycle"
operator: "Equal"
value: "Ec2Spot"
effect: "NoSchedule"
⚠️ 適切なtolerationがなければ、PodはTaintされたノードにスケジュールされません。
推奨される組み合わせ
| ユースケース | 戦略 |
|---|---|
| Spotノードのみにスケジュール | nodeSelectorまたはnodeAffinity + Spot用のtoleration |
| 高メモリインスタンスを優先 | nodeAffinity内でpreferredDuringSchedulingIgnoredDuringExecutionを使用 |
| AZまたはゾーンの必須要件 | nodeAffinity内でINLINE_CODE_PLACEHOLDER_ae23854027729f3aを使用 |
| デフォルトでTaint付きGPUノードを回避 | GPUが必要でない限りtolerationを定義しない |
💡 プロのヒント: ノードに明確なラベルを付け(例: workload-type=stateless、lifecycle=spot)、nodeAffinityとtolerationsを組み合わせて使用することで、スケジューラーを過度に制約することなくトラフィックを賢く誘導できます。
結論:スケジューリングは隠れたコスト削減レバー
スマートなKubernetesスケジューリングは、単なるパフォーマンス戦略ではなく、コスト管理メカニズムでもあります。適切な設定により、以下が可能になります:
- スポット利用の最大化
- ビンパッキング効率の向上
- リソース無駄の最小化
- 高価なオンデマンドノードへの依存軽減
数百のノードを管理している場合でも、EKSを始めたばかりの場合でも、CloudPilot AIのようなプラットフォームは、安定性を犠牲にすることなくコストを最適化するための技術的優位性を提供します。









