
会社概要
2010年に設立されたNetvueは、ホームセキュリティ監視に重点を置いたスマートホームのハードウェアおよびソフトウェアソリューションのグローバルリーダーです。
高度な監視ハードウェアとインテリジェントなクラウドサービスを組み合わせることで、Netvueはリアルタイムのビデオ監視と自動脅威検出を可能にしています。同社は世界中で100万人以上のユーザーにサービスを提供し、40以上の特許を保有しています。
課題
高いGPUコストと限られた弾力性
コンプライアンス要件を満たし、トラフィックの急増に対応するため、NetvueはGoogle CloudのGPUインスタンス上にAI推論サービスを展開しました。しかし、ユーザーベースが拡大するにつれて、関連するGPUコストが急速に増加し、ビジネスの拡張性に大きな障壁となりました。
Netvueには一部の自動スケーリング機能が導入されていましたが、インスタンスの選択は主に手動で行われていました。これにより、スポットインスタンスなどのよりコスト効率の高いリソースを活用することが困難でした。
クラウドネイティブなスケジューラ(Kubernetesなど)がないことでさらに柔軟性が制限され、GPUサービスはGoogle Cloudにロックインされ、アップグレードや展開が複雑になっていました。
急激なトラフィックと一貫性のない需要
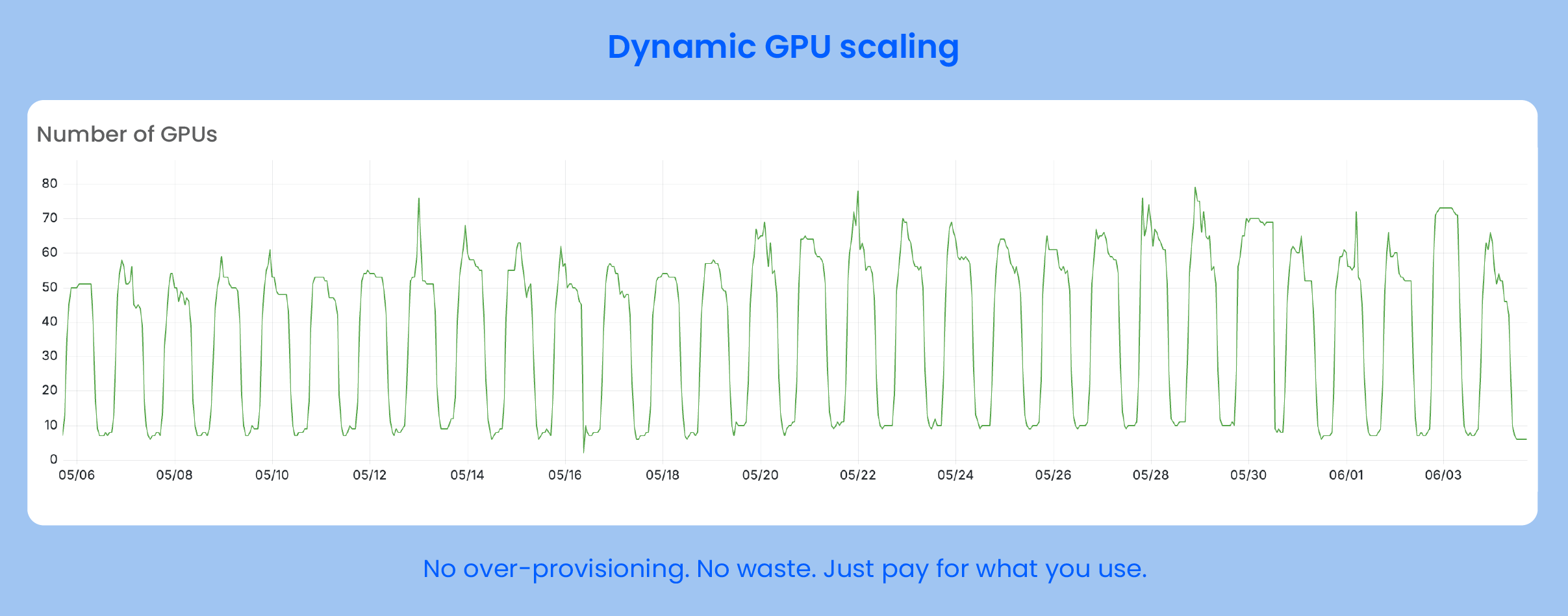
ユーザートラフィックは昼夜で大きな変動を示しました。ピーク時間帯には、GPUワークロードが急速に増加し、従来のスケジューリング戦略の限界が露呈しました。これにより、リソースの競合やコールドスタートが発生することがあり、モデル推論速度とユーザーエクスペリエンスに影響を与えていました。
クロスクラウドのオーバーヘッドとレイテンシー
Netvueは画像と動画データをAWS S3に保存し、推論サービスはGCP上で実行され、専用インターコネクトで接続されていました。このクロスクラウド構成により、高い帯域幅コストが発生し、クラウド間のデータ転送によって推論レイテンシーが増加し、全体的なサービスパフォーマンスに悪影響を及ぼしていました。
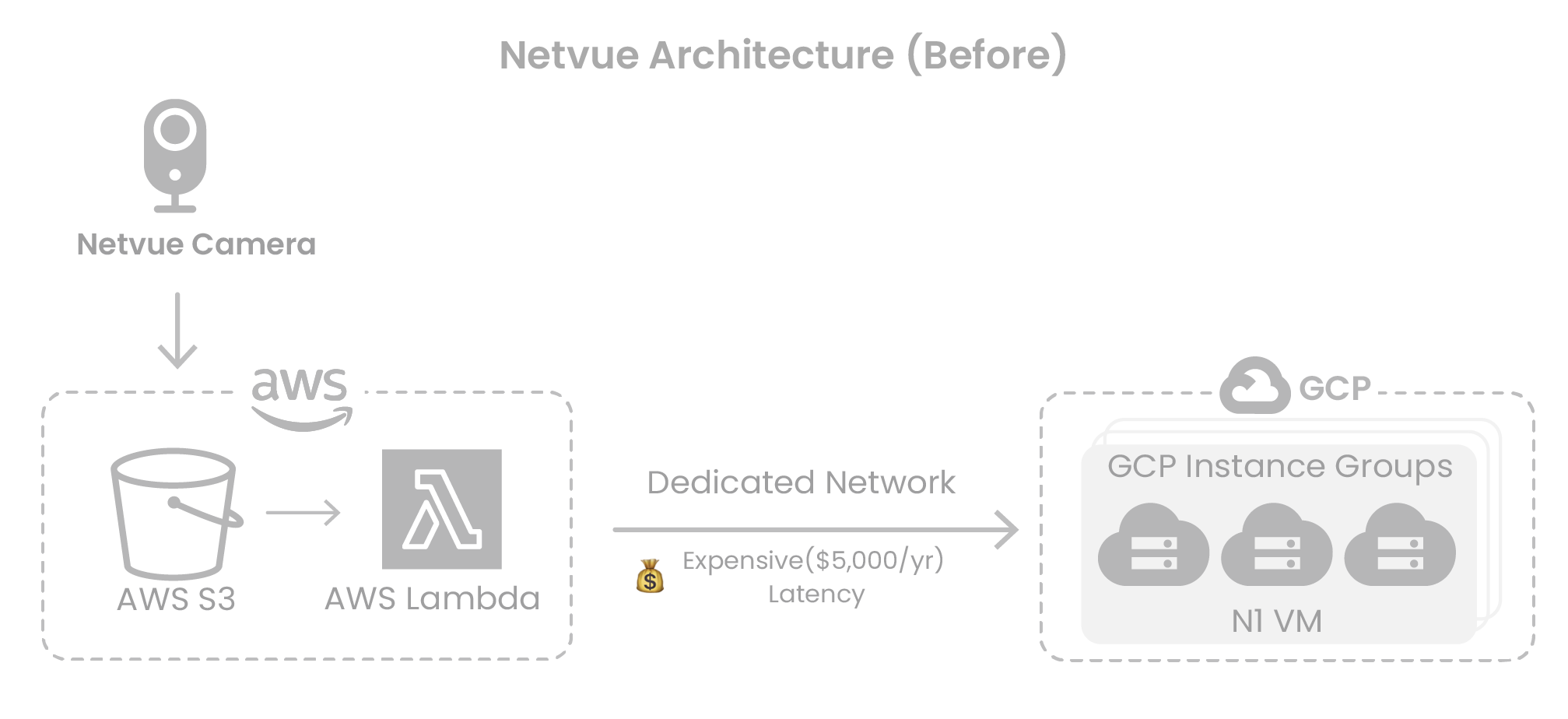
ソリューション:GPUスケジューリングアーキテクチャの再構築
結果
-
GPUコストの52%削減 インスタンス選択の最適化とスポットGPUの採用により、GPU1台あたりの月額コストが180ドル以上から約80ドルに削減されました。
-
柔軟でクラウドに依存しないスケジューリング Kubernetesベースの弾力的なGPUアーキテクチャを構築し、ベンダーロックインを排除しました。
-
5倍速いレスポンスタイム 計算処理とデータを同一場所に配置することで、クロスクラウドのレイテンシーを解消しました。
-
スケールでの安定した運用 ピーク時間帯の迅速なスケールアップと、オフピーク時の正確なスケールダウンにより、コスト効率とサービスの安定性の両方を確保しました。
増加するコストと限られた柔軟性に対処するため、NetvueはCloudPilot AIと提携し、既存のサービスロジックを大幅に変更することなく、GPUアーキテクチャを体系的に最適化しました。
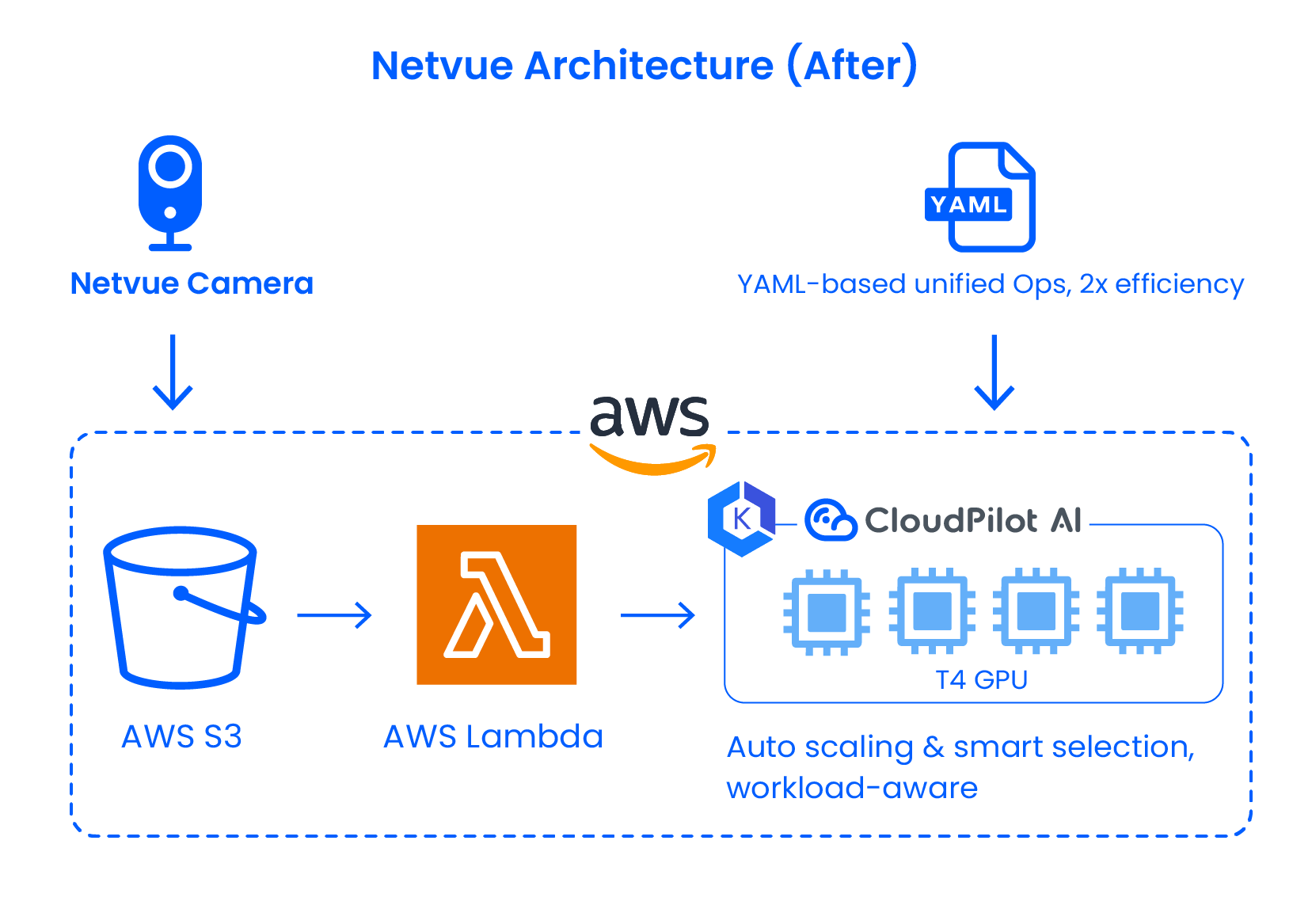
クラウドに依存しない弾力性のためのKubernetesへの移行
CloudPilot AIのサポートにより、Netvueは推論サービスをKubernetesに移行し、AWS上に専用GPUクラスターを立ち上げました。これにより、動的なGPUスケジューリング、自動スケーリング、複数のクラウド環境にわたる統合管理が可能になりました。新しいアーキテクチャはワークロードを基盤プラットフォームから切り離し、マルチクラウド展開の基盤を築きました。
インテリジェントなインスタンス選択:GCPからAWSへのスムーズなGPU移行
当初、Netvueは、AWSに適切なリソースがなかったため、GCP上でGPUワークロードをデプロイしていました。しかし、ほとんどのデータがAWSに存在していたため、クロスクラウド転送によって大きなパフォーマンスのボトルネックが発生していました。
CloudPilot AIのインスタンス推奨エンジンを使用することで、Netvueは正確な要件(例:T4/T4Gファミリーの優先)を定義し、AWS上で適切なSpot GPUを特定し、推論ワークロードをシームレスに移行しました。これにより、インターコネクトへの依存を排除しました。CloudPilotのSpot中断予測エンジンにより、ワークロードの安定性がさらに確保されました。
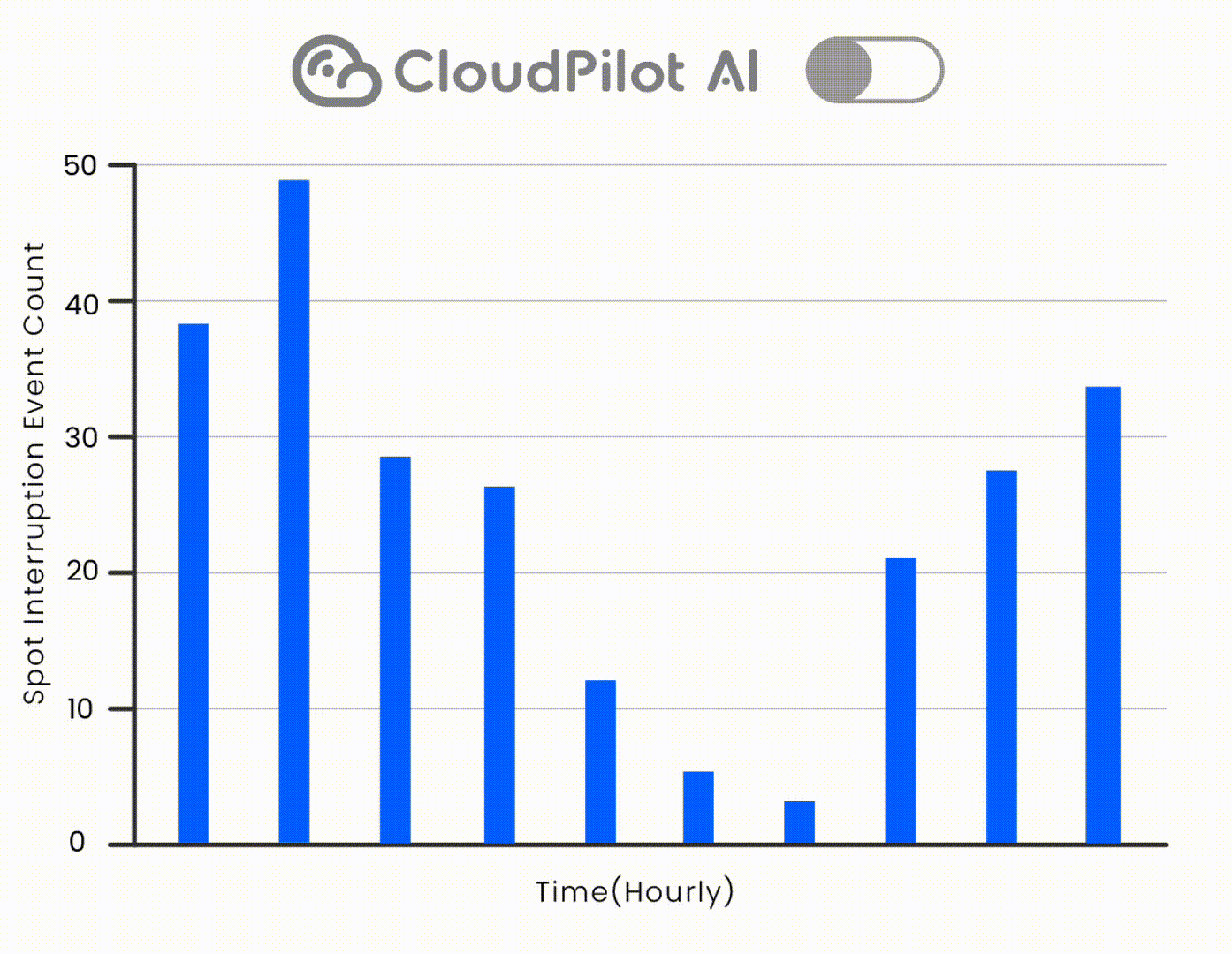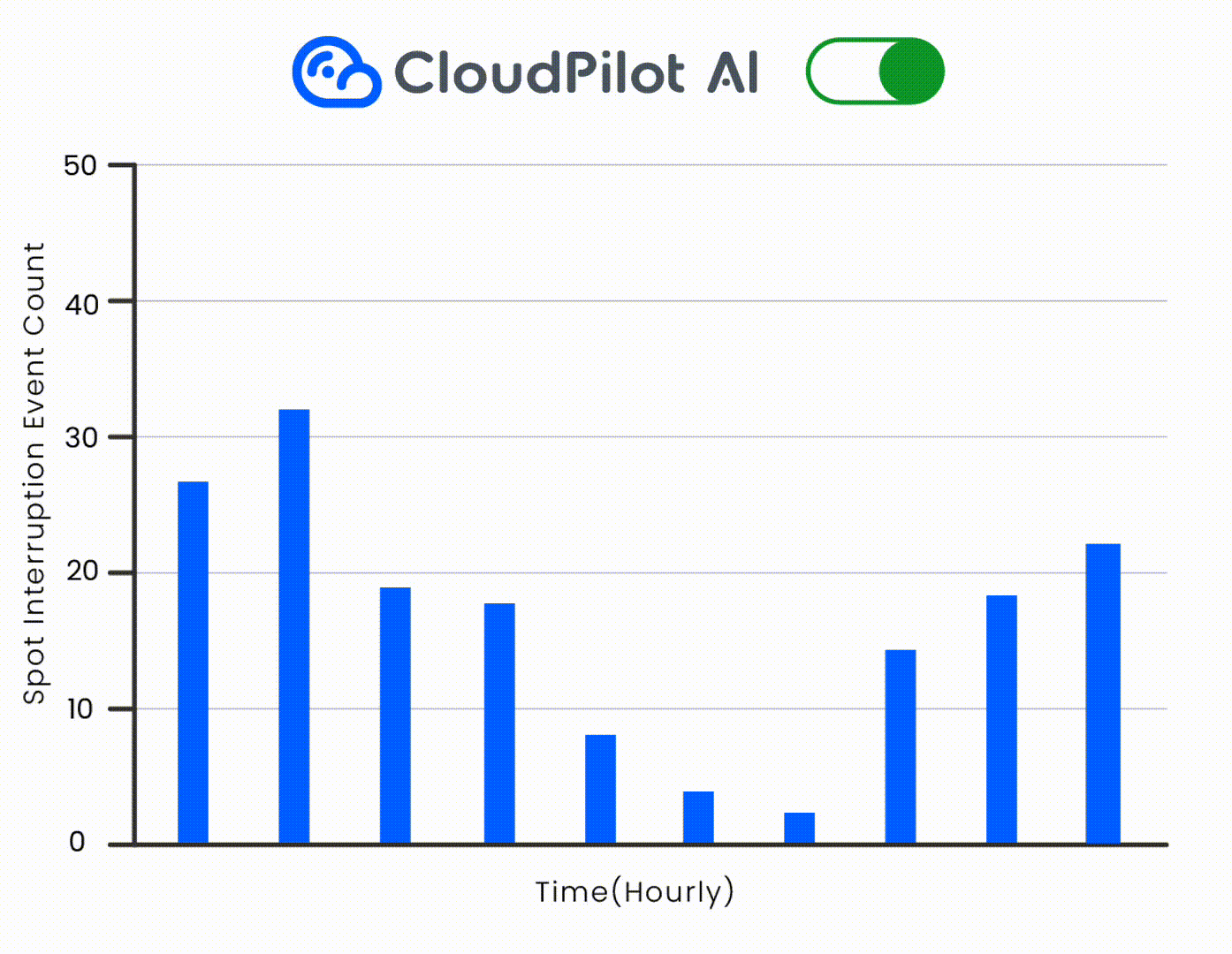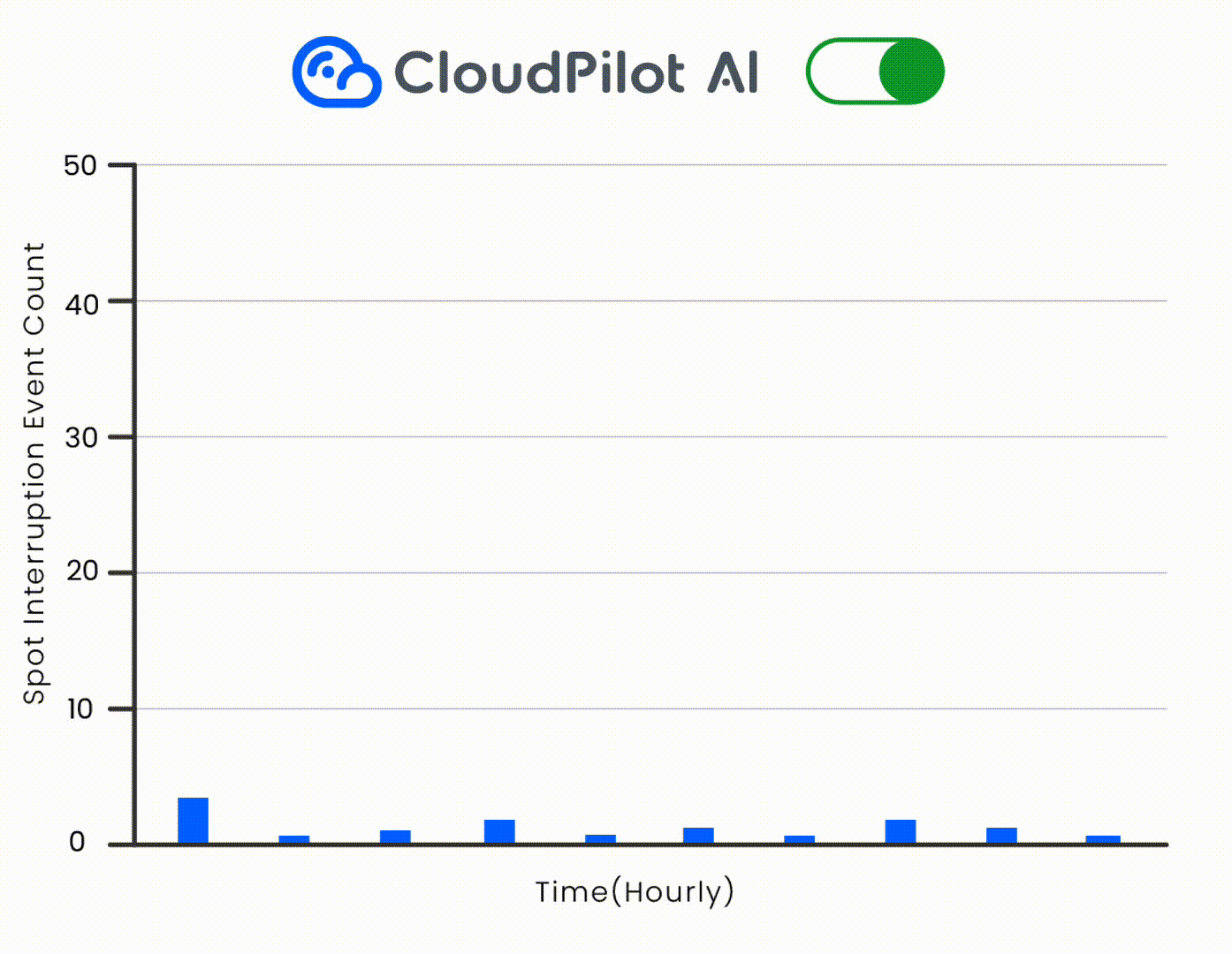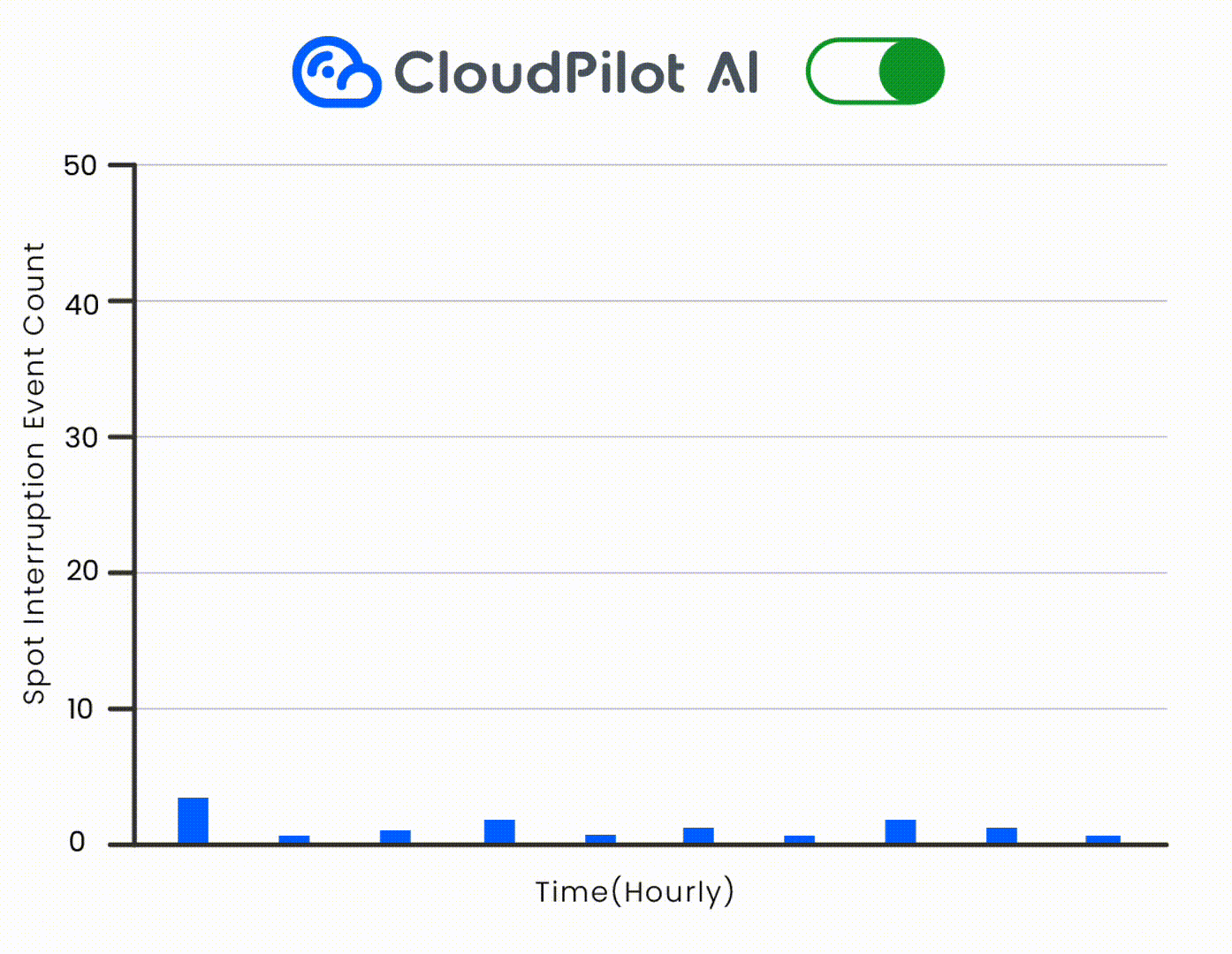
マルチアーキテクチャサポートによる幅広いGPUカバレッジ
Netvueはx86とARMベースのアーキテクチャ間でスケジューリングを可能にすることでGPUの可用性を拡大し、供給圧力を緩和し、ユニットあたりの計算コストを削減しました。
「ビジネスが急速に拡大するにつれて、クラウドでのGPUコストが大きな制約となりました」とNetvueのプラットフォーム開発責任者のオリバー・ファンは述べています。「CloudPilot AIは私たちのニーズを満たす最もコスト効率の良いリソースを見つけるだけでなく、時間の経過とともにより効率的に進化し運用するための柔軟性をインフラに提供してくれました。」
クラウドでのAI推論の実行:スケーリングとコストの課題
Netvueのインフラチームはどのようにビジネスの成長をサポートしていますか?
私たちのインフラチームは、Netvueのすべてのクラウドサービスをスムーズに運用する責任を負っています。クラスター管理やリソーススケジューリングからパフォーマンスチューニングやコスト管理まで、すべてを担当しています。エンジニアリングチームと緊密に連携して、ユーザーが世界中で安定した低レイテンシーの体験を得られるようにしています。
リアルタイムのパフォーマンスは私たちにとって非常に重要です。例えば、ユーザーは子供やペットをリアルタイムで監視するために私たちのカメラに依存しています。つまり、画像のアップロード、推論の実行、結果の配信をできるだけ速く処理する必要があります。
これをサポートするために、クラウドで大規模なGPU推論ワークロードを実行しています。エラスティックスケジューリングにより、トラフィックのスパイク時に迅速にスケールアップし、静かな時間帯にはスケールダウンすることができます。インフラは、AIプロダクト体験全体のバックボーンとなっています。
クラウドコスト最適化に取り組もうと決めた理由は何ですか?
主に2つの理由がありました。まず、GPUコストが急速に増加していました。ユーザーベースが拡大するにつれて、推論リクエストの数が急増し、クラウド料金が急速に上昇し始めました。次に、初期のアーキテクチャはリソーススケジューリングに関して非常に柔軟性がありませんでした。トラフィックのピーク時には、ただ耐えるしかないことが多く、これは持続可能な戦略ではありません。
パフォーマンスとコストのバランスを取るためのより良い方法が必要でした—効率的にスケールでき、単一のクラウドプロバイダーへの依存を減らすことができるものです。そのため、コスト最適化にもっと体系的なアプローチを取るためにCloudPilot AIと提携しました。
実践におけるクラウドGPUコスト最適化
CloudPilot AIとのオンボーディング体験はどのようなものでしたか?
CloudPilot AIを最初に統合する際には慎重なアプローチを取りました。チームは私たちと緊密に協力して、すべてが私たちのインフラに適合することを確認しました。その実践的なサポートにより、ツールから価値を得る方法を素早く理解することができました。
CloudPilot AIはまず環境を分析・評価し、貴重な推奨事項を提供しました。最初は、スポットGPUインスタンスの推奨事項やスケジューリングの最適化などの自動化戦略を非本番環境でパイロット実施しました。本番環境を混乱させないように非常に注意し、まずそこで徹底的なテストを実施しました。
テスト環境での複数回の安定した検証ラウンドを経て、私たちは段階的にこの戦略を本番環境に展開しました。プロセス全体を通じて、CloudPilot AIの透明性と制御性に感銘を受けました—すべての提案はデータに裏付けられており、すぐに完全な自動化を強制するのではなく、段階的に実装することができました。
どのCloudPilot AI機能があなたのチームに最も役立ちましたか?
最も役立った機能は、インテリジェントなノード選択とマルチアーキテクチャGPUスケジューリングでした。
以前はAWSで適切なGPUを見つけることができなかったため、GCPに依存していました。CloudPilot AIを使用することで、「A10またはT4を優先」などの要件を定義し、AWSで安定したコスト効率の良いスポットインスタンスを自動的に見つけることができ、ワークロードを移行することが可能になりました。
さらに、マルチアーキテクチャのサポートによりリソースプールが大幅に拡大し、最も人気のあるインスタンスだけに依存する必要がなくなりました。
インテリジェントなノード選択機能をどのように使用していますか?
「A10またはT4 GPUを優先」などの基準を設定すると、CloudPilot AIは自動的にこれらの仕様に一致する最も安定したコスト効率の良いAWSのスポットインスタンスを検索します。以前は、このような絞り込みをサポートするツールがなかったため、適切なAWS GPUを見つけることができず、諦めていました。CloudPilot AIを使用することで、利用可能なインスタンスをすぐに特定し、サービスを正常に移行することができました。
CloudPilot AIでどのような結果を達成しましたか?
最も直接的な影響は、GPU費用が52%削減されたことです。また、より柔軟なリソーススケジューリングを備えたKubernetesベースのクラウドに依存しないアーキテクチャを構築しました。サービスをAWSに移行した後、データと推論ワークロードの両方が同じプラットフォーム上で実行されるようになり、レイテンシーが大幅に削減されました。
さらに重要なのは、コールドスタートやリソース制限を心配することなく、トラフィックの急増に簡単に対応できるようになったことです。このコスト削減とパフォーマンス向上の組み合わせにより、インフラストラクチャがボトルネックからビジネス成長の原動力へと変わりました。
次のステップは?
CloudPilot AIにより、Netvueはグラフィックプロセッサのスケジューリングを最適化し、推論コストを削減し、インフラ投資を成長促進要因に変えました。継続的な最適化により、サービス品質、リソースの柔軟性、市場競争力が向上し続けています。
次に、Netvueはスポットグラフィックプロセッサの中断予測を統合してピーク負荷時の安定性を向上させ、グローバルに分散した高可用性の推論ネットワークを構築して、AIサービスのグローバル展開をサポートする予定です。









