
Company Overview
Founded in 2010, Netvue is a global leader in smart home hardware and software solutions, with a strong focus on home security monitoring.
By combining advanced surveillance hardware with intelligent cloud services, Netvue enables real-time video monitoring and automated threat detection. The company serves over 1 million users worldwide and holds more than 40 patents.
Challenges
High GPU Costs and Limited Elasticity
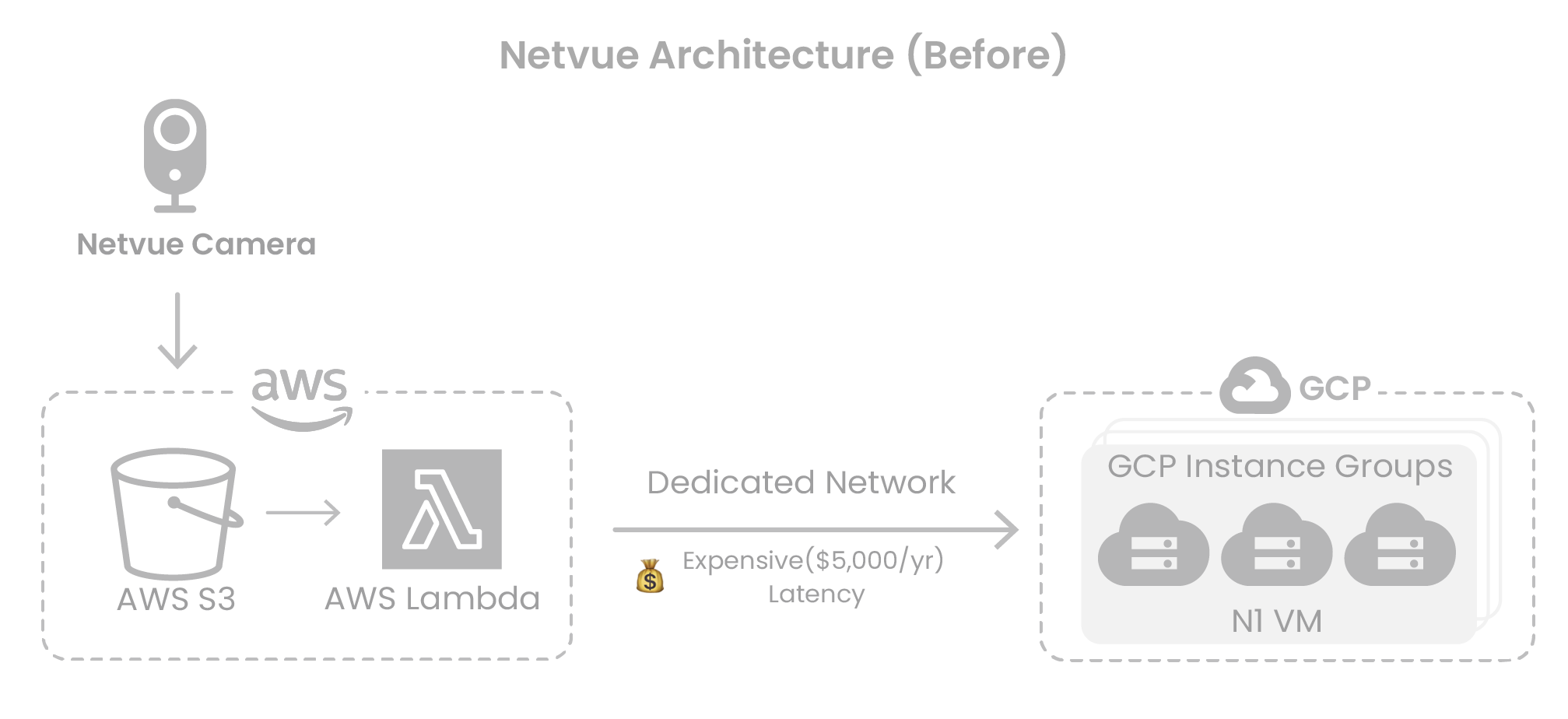
To meet compliance requirements and manage traffic surges, Netvue deployed its AI inference services on GPU instances in Google Cloud. However, as the user base expanded, the associated GPU costs grew rapidly, becoming a major barrier to business scalability.
While Netvue had some auto-scaling capabilities in place, instance selection remained largely manual. This made it difficult to take advantage of more cost-effective resources like spot instances.
The lack of a cloud-native scheduler (e.g., Kubernetes) further limited flexibility and the GPU services were locked into Google Cloud, complicating upgrades and deployments.
Spiky Traffic and Inconsistent Demand
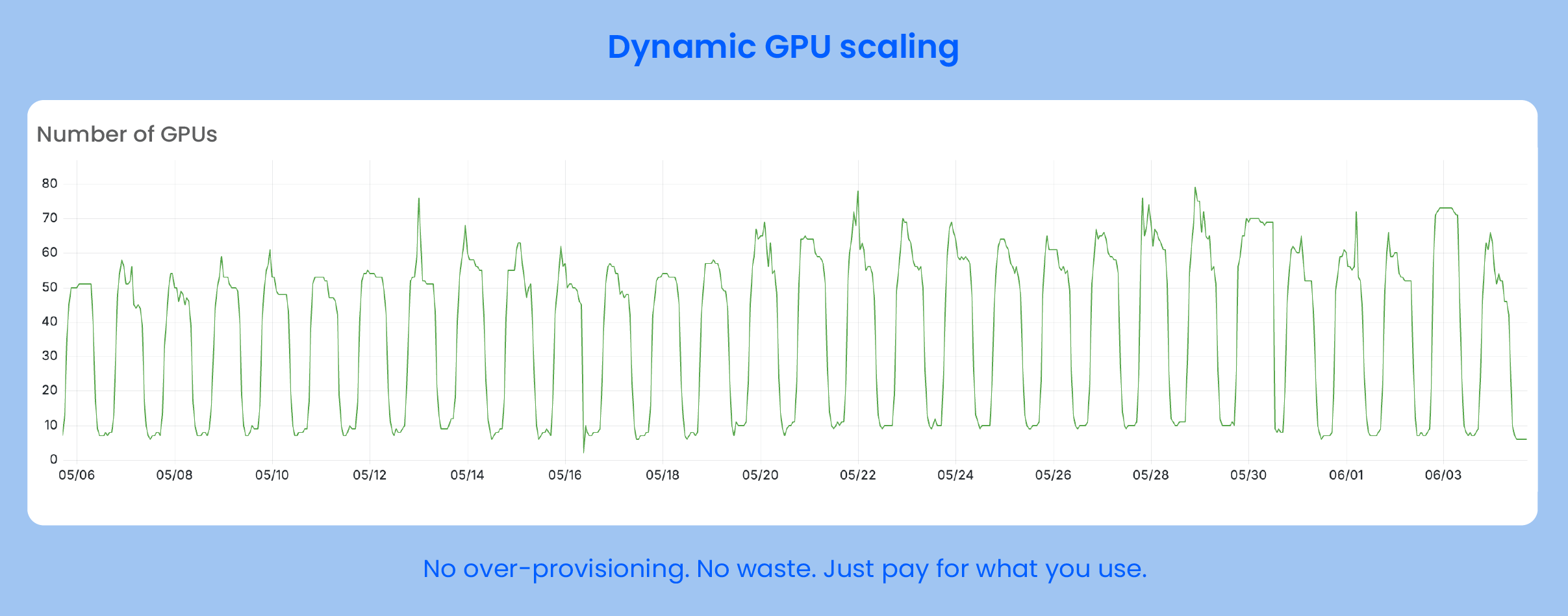
User traffic showed significant day-night fluctuations. During peak hours, GPU workloads surged rapidly, exposing the limitations of traditional scheduling strategies. This occasionally led to resource contention and cold starts, impacting model inference speed and user experience.
Cross-Cloud Overhead and Latency
Netvue stored image and video data in AWS S3, while its inference services ran on GCP, connected via dedicated interconnect. This cross-cloud setup introduced high bandwidth costs and increased inference latency due to inter-cloud data transfers — negatively affecting overall service performance.
Solution: Rebuilding GPU Scheduling Architecture
Results
-
52% reduction in GPU costs Optimized instance selection and adoption of Spot GPUs reduced per-GPU monthly cost from over $180 to around $80.
-
Flexible and cloud-agnostic scheduling Built a Kubernetes-based elastic GPU architecture, eliminating vendor lock-in.
-
5× faster response time Co-locating compute and data eliminated cross-cloud latency.
-
Stable operations at scale Rapid scaling during peak hours and precise downscaling during off-peak times ensured both cost efficiency and service stability.
To address rising costs and limited flexibility, Netvue partnered with CloudPilot AI to systematically optimize its GPU architecture—without overhauling its existing service logic.
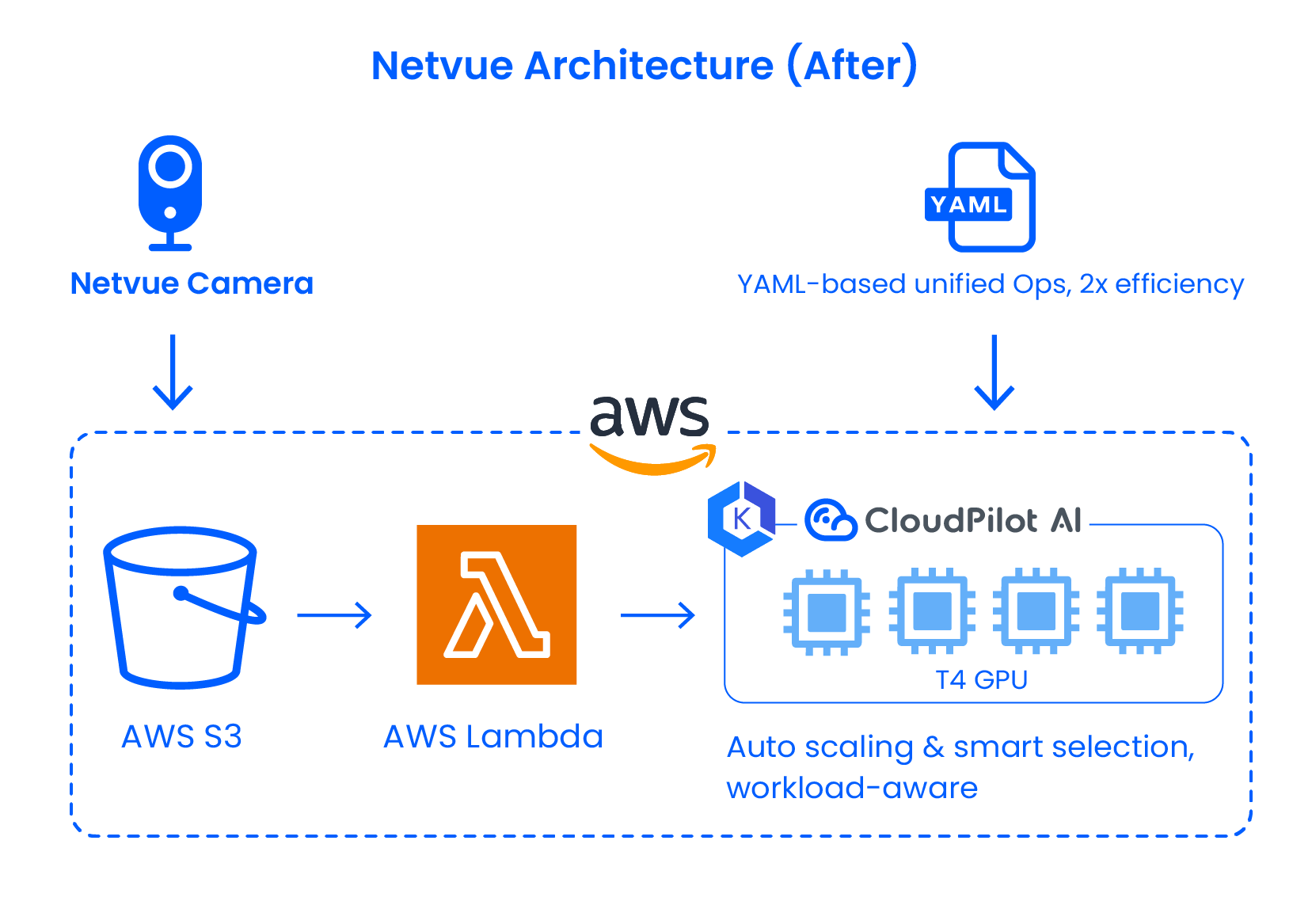
Migrating to Kubernetes for Cloud-Agnostic Elasticity
With CloudPilot AI's support, Netvue migrated its inference services to Kubernetes and launched dedicated GPU clusters on AWS. This enabled dynamic GPU scheduling, automatic scaling, and unified management across multiple cloud environments. The new architecture decoupled workloads from the underlying platform and laid the foundation for multi-cloud expansion.
Intelligent Instance Selection: Smooth GPU Migration from GCP to AWS
Initially, Netvue deployed GPU workloads on GCP due to unavailable suitable resources on AWS. However, with most data residing in AWS, cross-cloud transfers introduced significant performance bottlenecks.
Using CloudPilot AI's instance recommendation engine, Netvue defined precise requirements (e.g., prioritizing T4/T4G families), located suitable Spot GPUs on AWS, and migrated inference workloads seamlessly—eliminating dependency on interconnects. CloudPilot's Spot interruption prediction engine further ensured workload stability.
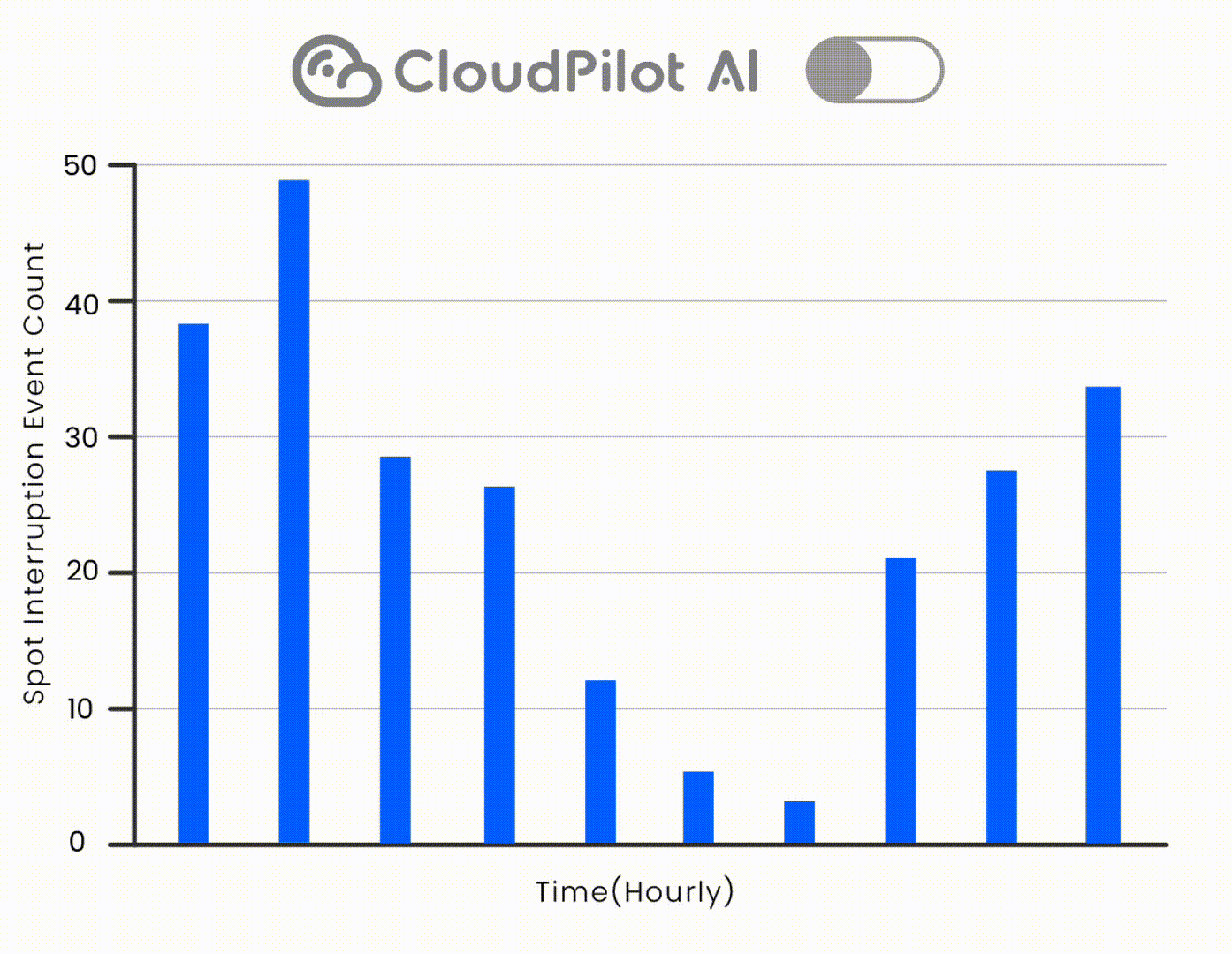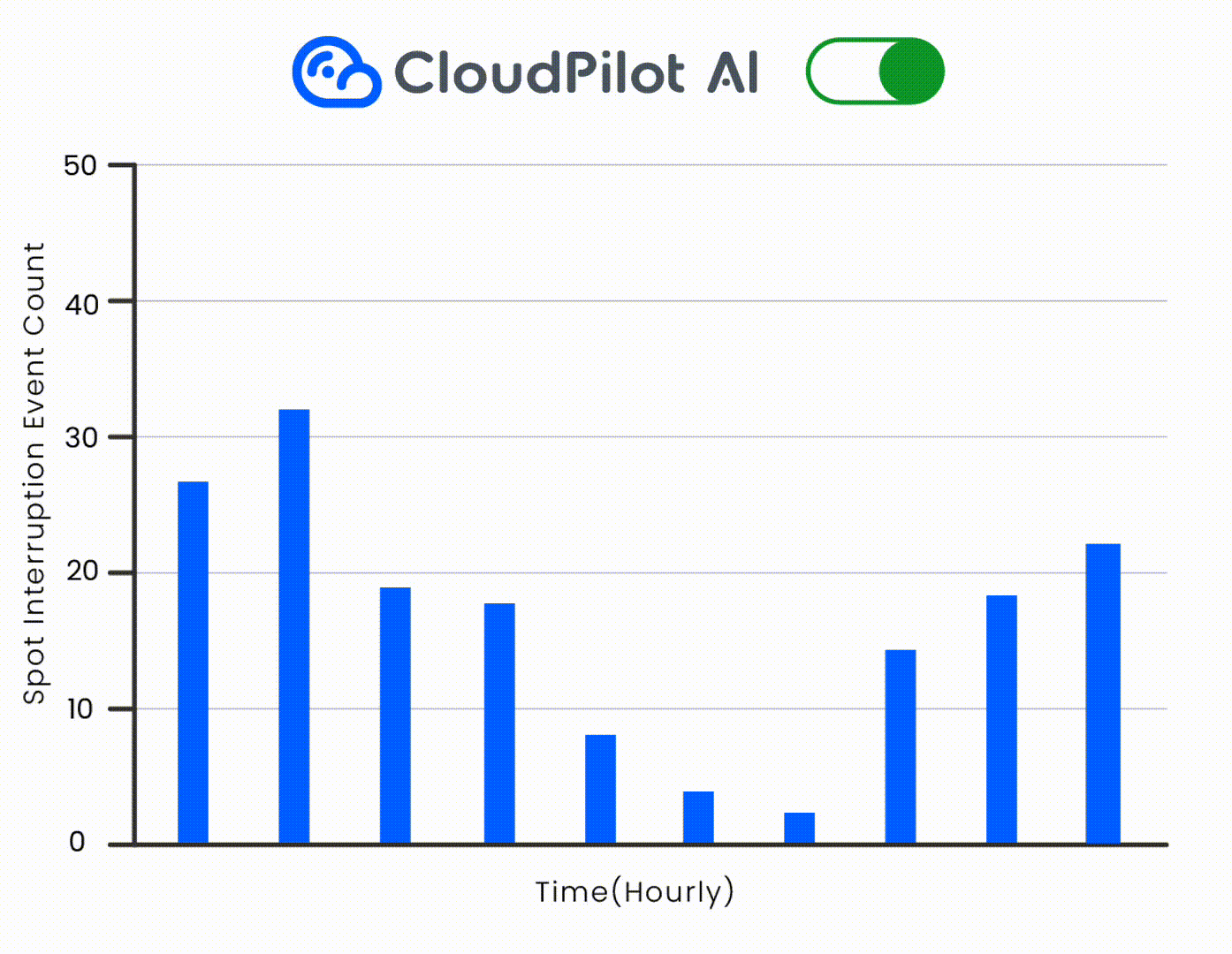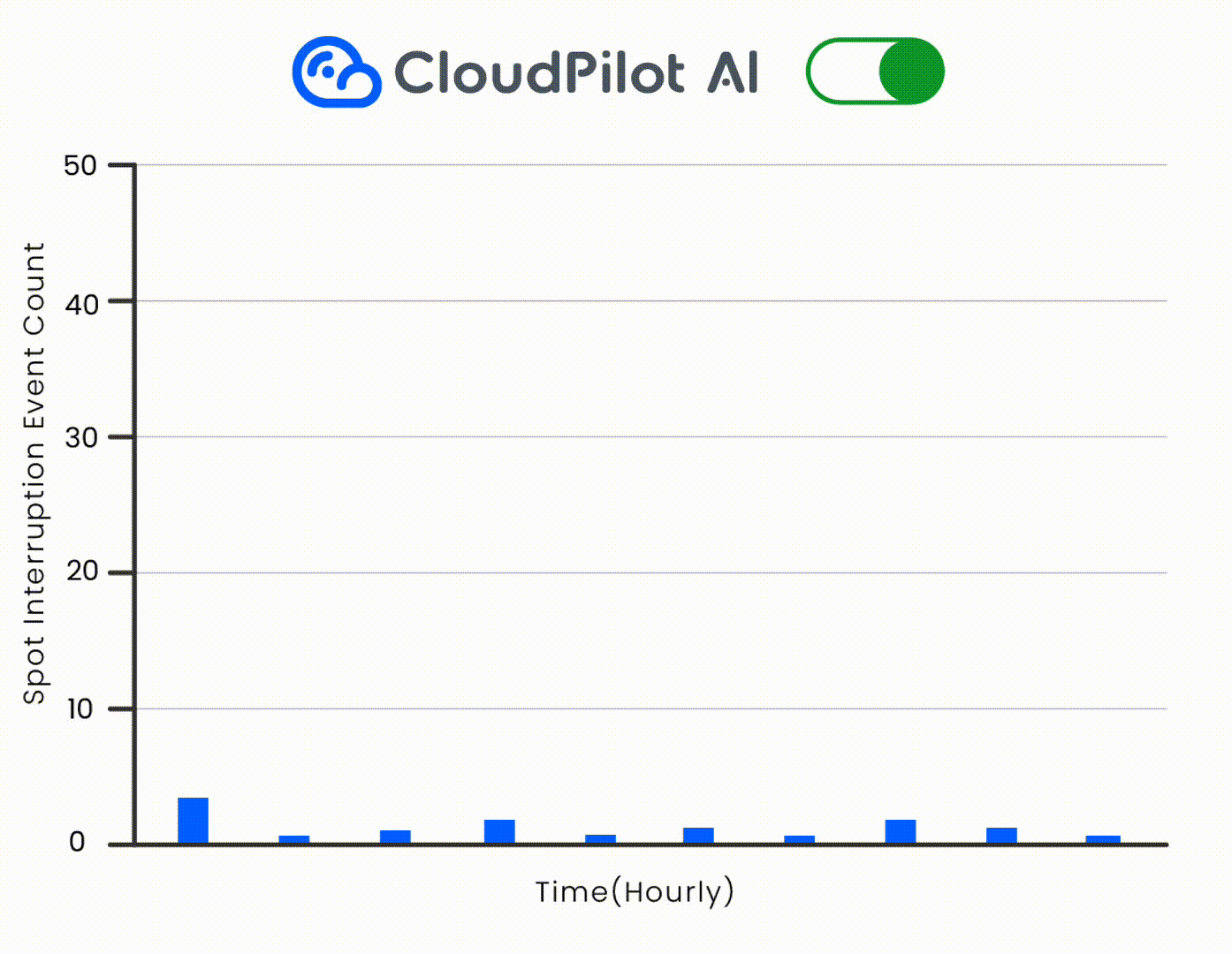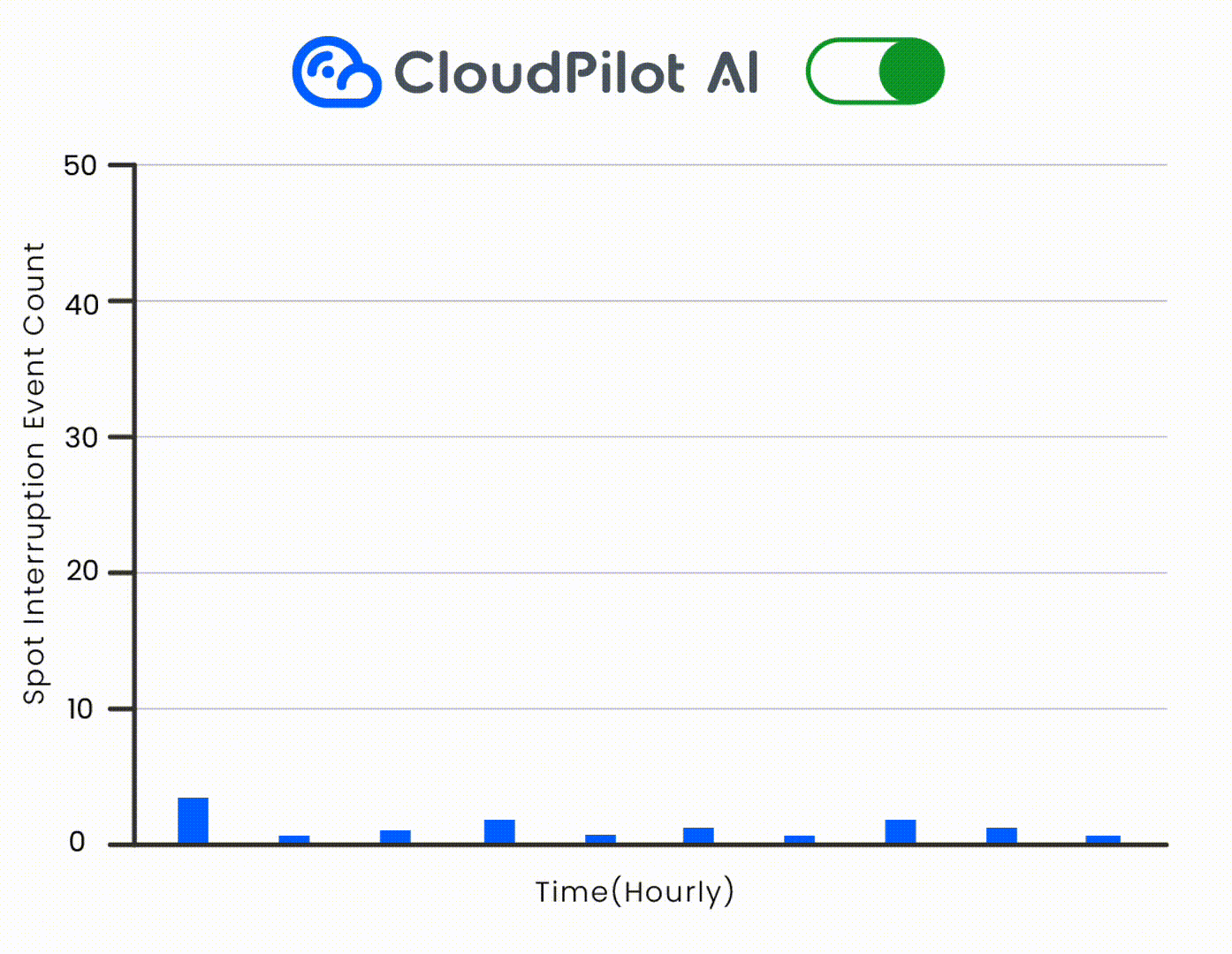
Broader GPU Coverage via Multi-Architecture Support
Netvue expanded GPU availability by enabling scheduling across x86 and ARM-based architectures, easing supply pressure and lowering per-unit compute cost.
"As our business scaled rapidly, GPU costs in the cloud became a major constraint," said Oliver Huang, Head of Platform Development at Netvue. "CloudPilot AI not only helped us find the most cost-effective resources to meet our needs, but also gave our infrastructure the flexibility to evolve and operate more efficiently over time."
Running AI Inference in the Cloud: Challenges in Scaling and Cost
How does the Infra team at Netvue support business growth?
Our infrastructure team is responsible for keeping all of Netvue's cloud services running smoothly. We handle everything from cluster management and resource scheduling to performance tuning and cost control. We work closely with the engineering team to make sure users get a stable, low-latency experience across the globe.
Real-time performance is critical for us. For example, users rely on our cameras to monitor their children or pets in real time. That means we need to process image uploads, run inference, and deliver results as fast as possible.
To support this, we run large-scale GPU inference workloads in the cloud. With elastic scheduling, we can quickly scale up during traffic spikes and scale down during quiet hours. In a way, Infra is the backbone of the entire AI product experience.
What made you decide to optimize cloud costs?
There were two main reasons. First, GPU costs were growing rapidly. As our user base expanded, the number of inference requests surged, and our cloud bill started to climb fast. Second, our early architecture wasn't very flexible when it came to resource scheduling. During peak traffic, we often had to just ride it out — which isn't a sustainable strategy.
We needed a better way to balance performance and cost — something that could scale efficiently and reduce our reliance on a single cloud provider. That's why we partnered with CloudPilot AI to take a more systematic approach to cost optimization.
Cloud GPU Cost Optimization in Practice
What was your onboarding experience with CloudPilot AI like?
We took a careful approach when first integrating CloudPilot AI. The team worked closely with us to make sure everything fit our infrastructure. That hands-on support helped us quickly understand how to get value from the tool.
CloudPilot AI started by analyzing and assessing our environment, then provided valuable recommendations. Initially, we piloted their automation strategies—such as Spot GPU instance recommendations and scheduling optimizations—in our non-production environment. We were very careful not to disrupt production, so we ran thorough testing there first.
After multiple stable validation rounds in the test environment, we gradually rolled the strategy out to production. Throughout the process, we were impressed by CloudPilot AI's transparency and controllability—every suggestion was backed by data and could be implemented incrementally rather than forcing full automation right away.
Which CloudPilot AI features helped your team the most?
The features that benefited us most were intelligent node selection and multi-architecture GPU scheduling.
We used to rely on GCP because we couldn't find suitable GPUs on AWS. With CloudPilot AI, we defined requirements like "prefer A10 or T4," and it automatically found stable, cost-effective Spot instances on AWS—enabling us to migrate workloads back.
Additionally, multi-architecture support greatly expanded our resource pool, so we're no longer dependent on just the most popular instances.
How exactly do you use the intelligent node selection feature?
We set criteria like "prefer A10 or T4 GPUs," and CloudPilot AI automatically searches for the most stable and cost-effective Spot instances on AWS matching these specs. Previously, we couldn't find suitable AWS GPUs because no tools supported this kind of filtering, so we gave up. With CloudPilot AI, we quickly pinpointed available instances and successfully migrated our services back.
What results have you achieved with CloudPilot AI?
The most direct impact is a 52% reduction in GPU costs. We also built a Kubernetes-based, cloud-agnostic architecture with more flexible resource scheduling. After moving services to AWS, both data and inference workloads run on the same platform, significantly reducing latency.
More importantly, we can now easily handle traffic spikes without worrying about cold starts or resource limits. This combination of cost savings and performance gains has turned our infrastructure from a bottleneck into a driver for business growth.
What's next?
With CloudPilot AI, Netvue has optimized GPU scheduling, reduced inference costs, and turned infrastructure spending into a growth enabler. Ongoing optimization continues to enhance service quality, resource flexibility, and market competitiveness.
Next, Netvue will integrate Spot GPU interruption prediction to improve stability during peak loads and build a globally distributed, highly available inference network to support the global scaling of its AI services.








