
もしクラウドの請求書を開いて「オートスケーリングを使っているのに、なぜKubernetesクラスターのコストが増え続けているのか?」と思ったことがあるなら、それはあなただけではない。多くのチームが同じ問題、すなわちリソースを過剰に割り当てたクラスターによる無駄遣い、あるいはリソース不足によるレイテンシやPodの退避、サービスの劣化に直面している。
Kubernetesはコンテナを効率的にオーケストレーションするよう設計されているが、ワークロードが適切にサイズ設定されていることを自動的に保証するわけではない。体系的なキャパシティプランニングがなければ、組織は「安心のためにコストを犠牲にする」か「コスト削減のために安定性を犠牲にする」かのいずれかに陥りがちである。このバランスを取る鍵がKubernetesキャパシティプランニングである。
Kubernetesキャパシティプランニングとは
Kubernetesキャパシティプランニングとは、CPU、メモリ、ストレージ、ネットワーク帯域といったインフラリソースの消費状況を理解・予測・最適化することである。これにより、ワークロードが常に安定して実行できるようにしつつ、無駄なリソース消費とクラウドコストを最小限に抑える。
キャパシティプランニングの本質は、パフォーマンスと効率性という二つの目標を橋渡しすることにある。リソースを十分に確保すれば安定性が得られるが、過剰な割り当てはコストの浪費につながる。そのため、クラスターがスムーズかつ予測可能にスケールし、財務的にも持続可能である「スイートスポット」を見つけることが重要である。
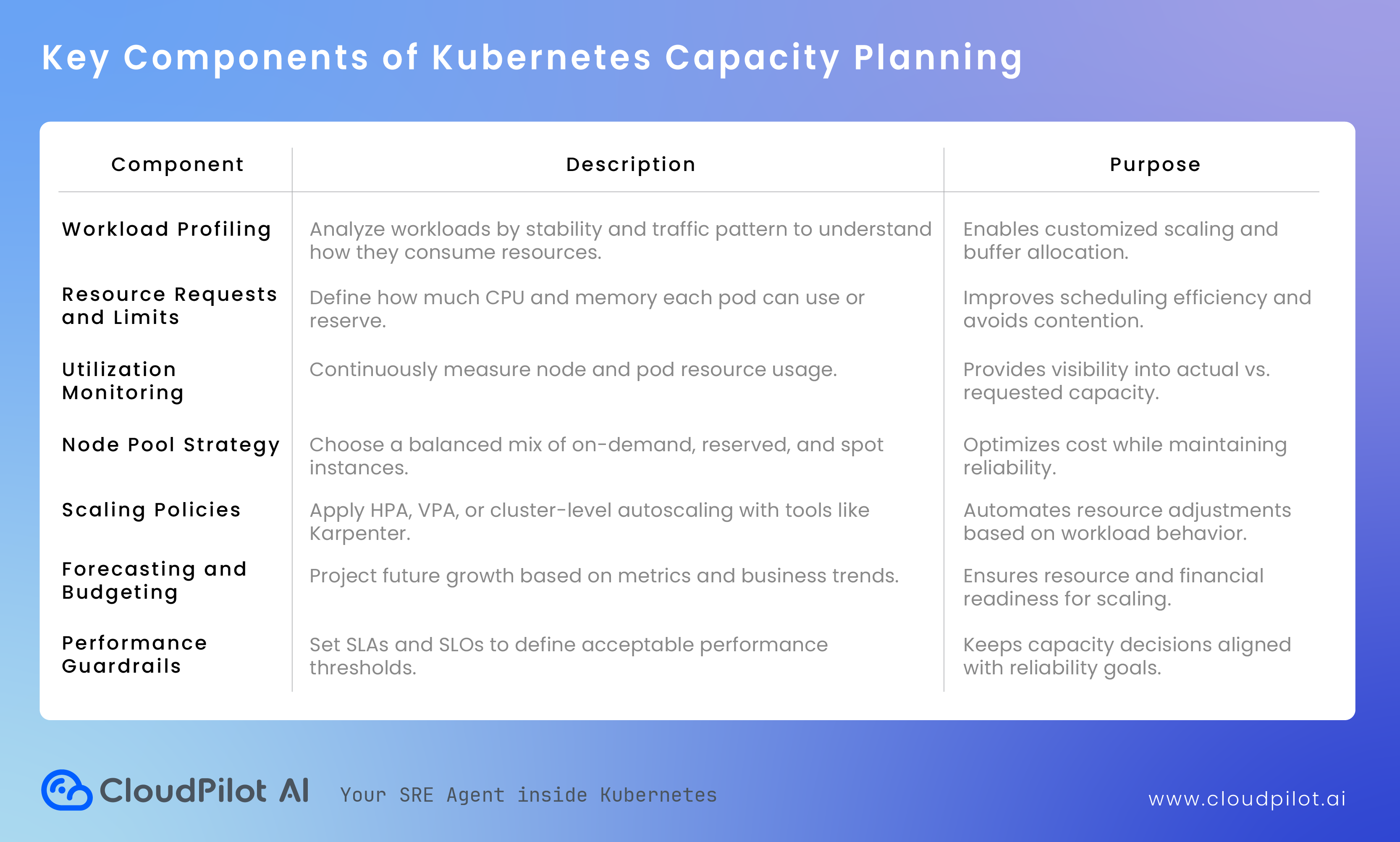
キャパシティプランニングは、通常次の三層で考慮される。
1. ワークロードレベルのプランニング
各アプリケーションは一定量のCPUとメモリをrequestとして宣言する。これらの値がスケジューラのPod配置に影響を与える。
requestが高すぎるとノードが過小利用され、低すぎるとリソース競合が発生する。
したがって、ワークロードのCPUスパイクやメモリ使用傾向を分析し、正確なrequestとlimitを設定することが基本である。
2. クラスタレベルのプランニング
ワークロードが適切にサイズ設定された後は、ノードの構成に焦点を当てる。必要なノード数、インスタンスタイプ、ゾーン分散、オンデマンド・リザーブド・スポットインスタンスのバランスを決める。
たとえば、安定したワークロードはリザーブドで、耐障害性のあるバッチジョブはスポットで運用するなどが可能である。
3. 戦略的な予測とスケーラビリティプランニング
日々のリソース配分に加え、キャパシティプランニングは将来を見据えた計画も含む。トラフィックの増加、新サービスの導入、リージョンの拡張などに備え、チームは将来の需要を予測する必要がある。予測には、過去の使用パターンや成長率を分析し、追加キャパシティがいつ必要になるかを見積もることが含まれる。
これにより、ピーク時にスケジューラ可能なノードが不足するなどの直前のスケーリング問題を回避でき、チームは予算やスケーリングポリシーを事前に計画できる。
Kubernetes におけるキャパシティプランニングは、技術的プロセスであると同時に戦略的プロセスでもある。エンジニアリングチームと財務チームが協力し、パフォーマンスデータとビジネス上の洞察を組み合わせて意思決定を行う必要がある。
技術面では、監視ツール、オートスケーラ、クラウド分析を活用して使用パターンを定量化する。戦略面では、長期的なインフラ投資の指針を示し、信頼性を損なうことなくスポットやセービングプランなどの最新価格モデルを採用することを支援する
キャパシティプランニングが重要な理由
1. コスト最適化
多くの Kubernetes 環境では、平均リソース利用率が50%未満であることが多い。これは、実際に必要なインフラの倍額を支払っている可能性があることを意味する。適切なキャパシティプランニングにより、非効率を特定し、過剰プロビジョニングを安全に削減し、コストを制御できる。
2. 安定したパフォーマンス
適切にサイズ設定されたクラスターは、リソース競合を防ぎ、重要なワークロードが常に必要な CPU とメモリを確保できる。これにより、パフォーマンスの一貫性が保たれ、OOM エラーの発生が減り、サービスの中断が最小限に抑えられる。
3. 予測可能なスケーラビリティ
将来のリソース需要を予測することで、アプリケーションの成長に応じてスムーズにスケールできる。キャパシティプランニングにより、クラスター拡張の際の試行錯誤が排除され、ピーク時の緊急ノード追加を回避できる。
4. ビジネス継続性
計画されたクラスターは、キャパシティ不足による障害を防ぐ。高可用性戦略をサポートし、スパイクや障害が発生しても、ユーザー向けサービスが継続的に稼働することを保証する。
キャパシティプランニングの仕組み
Kubernetes におけるキャパシティプランニングは、データ分析、予測、そして自動化を組み合わせたプロセスである。ワークロードがどのようにリソースを消費しているかを測定することから始まり、最終的にクラスターをどのようにスケールさせ、どのインスタンスタイプを使用するかを決定する。
1. 使用データの収集
まず、Prometheus、CloudWatch、Datadog などの監視ツールから実際の使用データを収集する。
特に注目すべきは、CPU とメモリのリクエスト、実際の使用量、Pod の再スケジュールやスロットリングの頻度である。これにより、現在のパフォーマンスと効率性のベースラインが確立される。
2. ワークロードの挙動分析
ワークロードによって需要パターンは異なる。安定的で予測可能なものもあれば、トラフィックやジョブスケジュールに応じてスパイクするものもある。
これらのパターンを分類することで、各ワークロードのニーズに応じたスケーリング戦略を設計し、リソースの無駄を最小化できる。
3. 将来の成長のモデル化
予測により、現在のキャパシティが需要を満たせなくなるタイミングを事前に把握できる。
過去のメトリクス分析 やビジネスの成長予測を活用し、ノード追加やインスタンスアップグレードを事前に計画することが可能である。
4. スケーリングポリシーの実装
需要パターンが明確になったら、Horizontal Pod Autoscaler(HPA)、Vertical Pod Autoscaler(VPA)、Karpenter などのスケーリングツールを用いて、動的にキャパシティを調整するポリシーを適用する。
これにより、トラフィックピーク時にはクラスターが拡張され、ワークロードがアイドル状態のときには縮小される。
5. 継続的な改善
キャパシティプランニングは一度で完了するものではない。ワークロードは進化し、使用パターンは時間とともに変化するため、継続的な監視と調整が必須である。
キャパシティプランニングプレイブック
フェーズ1:可視性の確立
1. リソースメトリクスの有効化
- 以下をインストール・設定する:
metrics-server- Prometheus と Grafana
- 次のメトリクスが取得可能であることを確認:
- Pod の CPU/メモリ使用量 (
container_cpu_usage_seconds_total,container_memory_working_set_bytes) - ノードの利用率
- ペンディング Pod の数
- スロットリングや OOMKill イベント
- Pod の CPU/メモリ使用量 (
2. ベースラインデータの収集
-
平日・週末パターンをカバーするため、7~14日間データを収集
-
データのエクスポート例:
-
kubectl top pods --all-namespaces > resource-usage.txt,kubectl top nodes > node-usage.txt -
インストールと設定:
metrics-server- PrometheusとGrafana
-
以下のメトリクスが利用可能であることを確認:
- PodのCPUおよびメモリ使用量(
container_cpu_usage_seconds_total、container_memory_working_set_bytes) - ノード使用率
- 保留中のPod数
- スロットリングおよびOOMKillイベント
- PodのCPUおよびメモリ使用量(
2. ベースラインデータの収集
- 平日と週末のパターンを把握するため、最低7〜14日間実行します。
- データを以下の形式でエクスポート:
kubectl top pods --all-namespaces > resource-usage.txt、kubectl top nodes > node-usage.txt
追跡すべき主要メトリクス
| メトリクス | 理想範囲 | 重要性 |
|---|---|---|
| CPU 利用率 | 60–80% | 下回ると無駄、高すぎるとスロットリングリスク |
| メモリ利用率 | 60–75% | メモリスパイクは OOM エラーを引き起こす |
| ペンディング Pod | 総数の0–2% | スケジューリングやクォータ問題の指標 |
| ネームスペース別コスト | 減少傾向 | 効率の追跡 |
フェーズ2:非効率の分析と特定
1. リクエストと実使用量の比較
kubectl get pods -A -o=custom-columns=NAME:.metadata.name,REQ_CPU:.spec.containers[*].resources.requests.cpu,REQ_MEM:.spec.containers[*].resources.requests.memory
kubectl get pods -A -o=custom-columns=NAME:.metadata.name,REQ_CPU:.spec.containers[*].resources.requests.cpu,REQ_MEM:.spec.containers[*].resources.requests.memory
**2. 過剰プロビジョニングの検出
実使用量がリクエストの50%未満の場合 → リサイズ候補
**3. 過少プロビジョニングの検出
実使用量がリクエストの90%超の場合 → スロットリングや OOMKill のリスク
**4. 自動化ツールの利用
- Goldilocks: 過去のメトリクスに基づきリクエスト/リミットを推奨
- CloudPilot AI Workload Autoscaler: リアルタイム利用状況と傾向に基づき自動でリソースを調整
フェーズ3:リソースリクエストとリミットの最適化
1. 新しいリクエスト/リミットの設定
- 観測された使用量の80パーセンタイルをリクエスト値として設定する
- リミットは必要に応じて設定(例:メモリ集約型やバースト性ワークロード)
2. 徐々に変更を適用
-
1つのネームスペースやデプロイメントグループ単位で更新
-
ローリングデプロイを利用して影響を最小化:
kubectl rollout restart deployment <name>kubectl rollout restart deployment <name>- Grafana ダッシュボードで確認:
- 新たな OOMKill やスロットリングの発生
- リソース利用率の改善
- スケジューリング遅延の有無
- Grafana ダッシュボードで確認:
💡 ヒント:
requests = limits に設定することは避ける。バースト容量を残すことで、バインパッキングやスケジューリング効率が向上する。
💡 ヒント:
requests = limitsを設定することは避けてください。バーストキャパシティを確保することで、ビンパッキングとスケジューリングの効率が向上します。
1. 基本ノード数の算定
-
平均ノード利用率を計算
-
計算式:
Required Nodes = (Total Pod CPU Requests / Node CPU Capacity) × Safety BufferRequired Nodes = (Total Pod CPU Requests / Node CPU Capacity) × Safety Buffer
2. ノードタイプの最適化
| ワークロードタイプ | 推奨ノードタイプ |
|---|---|
| 計算集約型 | c6i / c7g |
| メモリ集約型 | r6i / r7g |
| バースト/バッチ | スポットインスタンス |
| ML / GPU ジョブ | g5 / a10g |
3. Karpenter または Cluster Autoscaler の使用
- Karpenter を設定して最適ノードを動的に起動:
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m6i.large", "m6i.xlarge"]
limits:
resources:
cpu: 1000
- オンデマンドおよびスポットキャパシティ用に異なるノードプールを設定する。
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m6i.large", "m6i.xlarge"]
limits:
resources:
cpu: 1000
- クリティカルなワークロードや急激なスパイクに備えて、少なくとも15~25%の余剰キャパシティを確保する。
フェーズ5:予測と予算
1. 過去の成長分析
- Prometheusまたはクラウドコストツールを使用して、3~6か月の成長トレンドをグラフ化する。
- CPU時間、メモリGB時間、ノード数を時間経過で追跡する。
2. 将来の需要予測
- トレンドベースの予測を適用する:
Future Capacity = Current Usage × (1 + Growth Rate) × Safety Margin
- 例:400コア × (1 + 0.25) × 1.2 = 600コア。
Future Capacity = Current Usage × (1 + Growth Rate) × Safety Margin
- 「トラフィックが2倍になった場合どうなるか?」
- 「ジョブの30%をスポットに移行した場合どうなるか?」
- 予算とスケーリング戦略をそれに応じて調整する。
フェーズ6:継続的なレビューと自動化
1. 月次レビュー
- 予測使用量と実際の使用量を比較する。
- 新たに過剰プロビジョニングされた名前空間を特定する。
- ワークロードまたは環境ごとのコストを見直す。
2. 四半期ごとの最適化
- 新しい価格オプションに基づいてノードインスタンスタイプを更新する。
- リザーブドインスタンスおよびセービングプランの利用状況を見直す。
3. スケーリングの自動化
- 以下と統合する:
- 水平ポッドオートスケーラー(アプリケーションレベルのスケーリング用)
- 垂直ポッドオートスケーラー(自動的な適切なサイズ調整用)
- Karpenter(予測的ノードプロビジョニング用)
4. アラート設定
- 以下のアラートを設定する:
- ノードのCPU/メモリが90%に達した場合
- ポッドの保留率が高い場合
- 異常なコストの急増
Kubernetesキャパシティプランニングチェックリスト
- メトリクスの収集が完全かつ正確である
- リソースリクエストが観測された80パーセンタイルの使用量に一致している
- 成長予測がレビューされ、予算が承認されている
- オートスケーリングポリシーが調整され、テスト済みである
- キャパシティ飽和に対するアラートが設定されている
- 定期的なレビューサイクルが確立されている
CloudPilot AIがキャパシティプランニングにどのように役立つか
Kubernetesでの手動キャパシティプランニングは複雑で時間がかかります。リソースパターンは時間単位で変化し、ワークロードが進化し、スポット価格は常に変動します。CloudPilot AIは、ワークロードおよびノードレベルでの自律的な最適化を導入することで、推測を排除します。
CloudPilot AIがキャパシティプランニングを継続的かつインテリジェントなプロセスに変える方法は以下の通りです:
- ワークロードレベルの最適化:リアルタイムのCPUおよびメモリ使用量に基づいてワークロードを自動的に適切なサイズに調整し、過剰割り当てを防ぎ、クラスタ密度を向上させる。
- ノードレベルの最適化:価格、パフォーマンス、可用性データを使用して、最適なインスタンスタイプ(スポット、オンデマンドを含む)を動的に選択する。
- インテリジェントなスケジューリング:ワークロードをノード間で効率的に配置し、最大限の利用率と安定性を確保する。
- 自律的スケーリング:Karpenterやオートスケーリングツールとシームレスに統合し、最適なキャパシティを維持しながら最大80%のコスト削減を実現する。
CloudPilot AIにより、キャパシティプランニングはプロアクティブかつ自動化されます。リソース問題に反応するのではなく、クラスタは継続的かつインテリジェントに、コスト効率よく最適化された状態を維持します。
- ワークロードレベルの最適化:リアルタイムのCPUとメモリ使用量に基づいてワークロードを自動的に適正サイズ化し、過剰割り当てを防止してクラスタ密度を向上させます。
- ノードレベルの最適化:価格、パフォーマンス、可用性データを使用して、最適なインスタンスタイプ(スポット、オンデマンドを含む)を動的に選択します。
- インテリジェントなスケジューリング:最大限の利用率と安定性を確保するため、ワークロードをノード間で効率的に配置します。
- 自律的なスケーリング:Karpenterや自動スケーリングツールとシームレスに統合し、コストを最大80%削減しながら最適な容量を維持します。
CloudPilot AIにより、キャパシティプランニングはプロアクティブかつ自動化されます。リソース問題に反応するのではなく、クラスタは継続的かつインテリジェントに、コスト効率よく最適化された状態を維持します。









